핵심 요약
MiniMax M3 발표에서 가장 눈에 띄는 말은 “첫 오픈웨이트 frontier 모델”이 아닙니다. 더 중요한 문장은 “코딩, 1M 컨텍스트, 네이티브 멀티모달을 한 모델에 묶었다”는 주장입니다. 최근 코딩 모델 경쟁은 단순히 함수 하나를 잘 짜는 능력에서 벗어나고 있습니다. 큰 저장소를 오래 들여다보고, 터미널을 쓰고, 실패한 테스트를 다시 읽고, 이미지나 문서까지 같이 해석하는 쪽으로 이동했습니다.
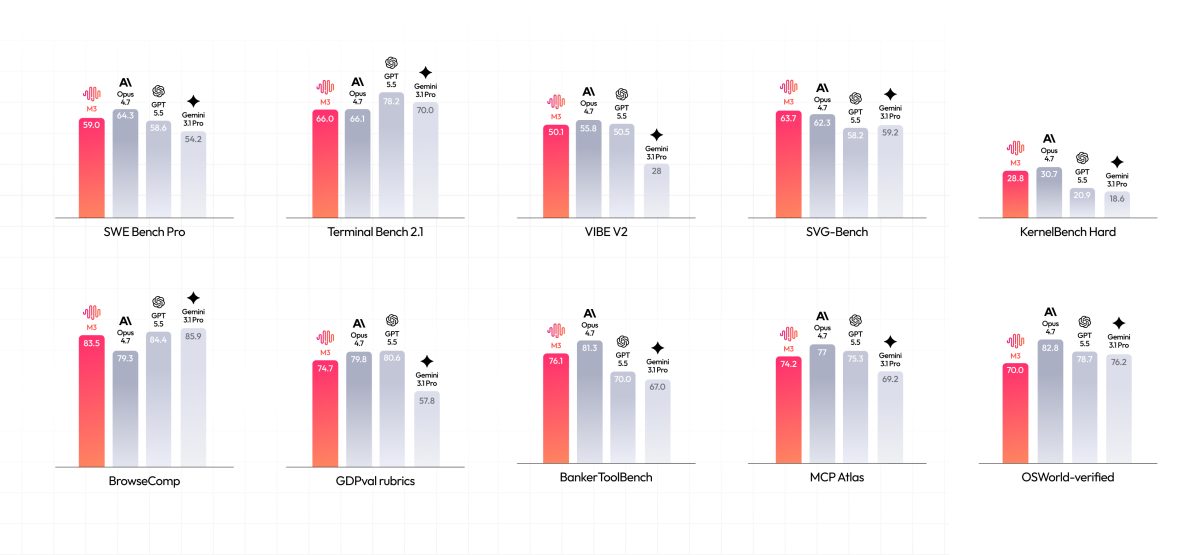
MiniMax는 2026년 6월 1일 M3를 공개하면서 1M 토큰 컨텍스트, MiniMax Sparse Attention, 줄여서 MSA, 코딩·에이전트 벤치마크, MiniMax Code 업데이트, Token Plan과 API 접근 경로를 함께 발표했습니다. 공식 블로그에 따르면 SWE-Bench Pro는 59.0%, Terminal-Bench 2.1은 66.0%, SWE-fficiency는 34.8%, KernelBench Hard는 28.8%, MCP Atlas는 74.2%입니다. 제품 페이지는 BrowseComp 83.5, PostTrainBench 37.1 같은 수치도 강조합니다.
하지만 이 글을 읽는 시점에서 가장 먼저 구분해야 할 것이 있습니다. 2026년 6월 2일 기준, M3 API와 MiniMax Code는 사용할 수 있지만, 모델 가중치와 기술 리포트는 아직 공개되지 않았습니다. MiniMax는 공식 블로그에서 “향후 10일 내” 기술 리포트와 대응 모델 가중치를 공개하겠다고 밝혔습니다. Hugging Face의 MiniMaxAI 조직 페이지에서도 최근 모델 목록은 MiniMax-M2.7, M2.5, M2.1, M2 등으로 보이며 M3 체크포인트는 아직 확인되지 않습니다.
이미지 출처: MiniMax 공식 M3 발표.
그래서 결론은 조심스럽습니다. M3는 오픈 모델 경쟁의 방향을 잘 보여주는 중요한 발표입니다. 다만 지금 당장 “로컬에 내려받아 Claude Code급 코딩 에이전트를 대체한다”는 식으로 말하기에는 이릅니다. 현재 단계의 핵심은 발표 수치를 외우는 것이 아니라, 가중치 공개 후 무엇을 검증해야 하는지 정리하는 것입니다.
이 글의 독자는 개발자와 AI 도구를 팀에 도입하려는 실무자입니다. 일반적인 AI 뉴스 요약이 아니라, MiniMax M3를 실제 코딩 워크플로에 넣기 전에 확인해야 할 성능, 비용, 라이선스, 하네스 의존성을 중심으로 보겠습니다.
발표의 핵심은 파라미터 수가 아니다
오픈 모델 발표는 오래동안 파라미터 수와 벤치마크 점수 중심으로 소비됐습니다. 몇 B인지, 어느 리더보드에서 몇 점인지, 특정 폐쇄형 모델을 이겼는지가 제목이 됐습니다. M3 발표는 그 흐름에서 조금 다릅니다. MiniMax가 전면에 건 것은 모델 크기보다 세 가지 사용 능력입니다.
첫째는 코딩과 agentic work입니다. 여기서 말하는 코딩은 코드 자동완성만 뜻하지 않습니다. 실제 저장소를 읽고, 이슈를 이해하고, 테스트를 실행하고, 터미널 출력에서 실패 원인을 찾고, 여러 번 수정하는 흐름입니다. 공식 발표의 CUDA kernel optimization 사례가 이 지점을 보여줍니다. MiniMax는 M3가 약 24시간 동안 147번의 benchmark submission과 1,959번의 tool call을 수행했고, FP8 GEMM 최적화에서 Hopper FP8 하드웨어 peak utilization을 7.6%에서 71.3%로 끌어올렸다고 설명합니다.
둘째는 1M 토큰 컨텍스트입니다. 긴 컨텍스트는 이제 “많이 넣을 수 있다”만으로 충분하지 않습니다. 저장소 전체, 문서, 로그, 실험 결과를 넣으면 편해 보이지만, 입력이 커질수록 비용과 지연시간, 주의 분산이 늘어납니다. 이전에 정리한 AI 코딩에서 컨텍스트 도구가 중요한 이유에서도 핵심은 “모델이 모든 것을 보는가”가 아니라 “필요한 파일과 근거를 제대로 고르는가”였습니다. M3의 1M 컨텍스트도 같은 기준으로 봐야 합니다.
셋째는 네이티브 멀티모달입니다. MiniMax는 M3가 이미지와 비디오 입력을 지원하고, 데스크톱 컴퓨터 조작까지 할 수 있다고 설명합니다. 이 부분은 코딩 모델과 무관해 보이지만 실제로는 연결됩니다. 프론트엔드 버그는 스크린샷과 렌더링 결과를 봐야 하고, 논문 재현은 figure와 수식, 표를 같이 읽어야 하며, 업무 자동화는 PDF, 엑셀, 브라우저, ERP 화면을 오갑니다. 코딩 에이전트가 점점 “텍스트만 보는 개발 보조 도구”에서 “작업 환경 전체를 다루는 에이전트”로 이동하는 배경입니다.
MSA가 해결하려는 문제
MiniMax는 M3의 핵심 기술로 MiniMax Sparse Attention, MSA를 제시했습니다. 공식 설명에 따르면 full attention은 컨텍스트가 길어질수록 계산량이 빠르게 커지는 구조적 문제가 있고, MSA는 KV를 더 정밀하게 block 단위로 나눠 필요한 정보를 다루는 sparse attention 방식입니다.
중요한 숫자는 두 가지입니다. MiniMax는 1M 컨텍스트 길이에서 M3의 토큰당 compute가 이전 세대 모델의 1/20 수준이라고 주장합니다. 또 1M 컨텍스트에서 prefill은 9배 이상, decoding은 15배 이상 빨라졌다고 설명합니다. 제품 페이지는 M3 API가 최대 1M 토큰 컨텍스트를 지원하며 최소 512K 토큰을 보장한다고 안내합니다.
이 숫자가 사실이라면 의미는 큽니다. 지금까지 1M 컨텍스트는 “기술적으로 가능하지만 매번 쓰기에는 부담스러운 기능”에 가까웠습니다. 큰 저장소 전체를 넣거나, 긴 영상·문서·실험 로그를 한 번에 넣는 일은 비용과 지연시간 때문에 실전에서는 선별 검색, RAG, 파일 요약, 세션 압축과 섞어 써야 했습니다. MSA의 주장은 바로 이 지점을 건드립니다. 긴 컨텍스트가 과시용 한도가 아니라 에이전트가 장시간 작업하는 기본 인프라가 될 수 있다는 주장입니다.
다만 여기에도 검증 포인트가 있습니다. sparse attention은 어떤 정보를 버리거나 덜 보느냐의 문제를 항상 동반합니다. 평균 벤치마크에서 좋아도, 특정 저장소에서 오래전에 읽은 작은 설정 파일 하나를 놓치면 실제 작업은 실패할 수 있습니다. 따라서 M3의 긴 컨텍스트 검증은 단순히 “1M 토큰 입력이 들어가는가”가 아니라 “멀리 떨어진 근거를 정확히 회수하는가”, “긴 도구 호출 기록 속에서 최신 실패 로그를 우선하는가”, “불필요한 파일 더미가 들어갔을 때 성능이 무너지지 않는가”로 봐야 합니다.
벤치마크 수치는 인상적이지만 내부 평가가 많다
MiniMax가 공개한 코딩·에이전트 수치는 공격적입니다.
| 항목 | MiniMax 공식 발표 수치 | 봐야 할 의미 |
|---|---|---|
| SWE-Bench Pro | 59.0% | 실제 PR 기반 소프트웨어 엔지니어링 문제 해결 능력 |
| Terminal-Bench 2.1 | 66.0% | 터미널 기반 장기 작업과 명령 실행 능력 |
| SWE-fficiency | 34.8% | 코딩 문제 해결 과정의 효율성 |
| KernelBench Hard | 28.8% | GPU kernel 최적화 같은 전문 코딩 능력 |
| MCP Atlas | 74.2% | MCP 기반 도구 사용·agentic task 수행 능력 |
| BrowseComp | 83.5 | 장기 탐색과 정보 회수 능력 |
| PostTrainBench | 37.1 | 데이터 합성, 훈련, 평가, 반복을 포함한 자율 연구 흐름 |
이 표만 보면 “오픈웨이트 모델이 폐쇄형 frontier 모델을 거의 따라잡았다”고 읽기 쉽습니다. 그러나 공식 블로그의 evaluation methodology를 보면 많은 항목이 MiniMax 내부 인프라와 특정 하네스 위에서 평가됐습니다. SWE-Bench Pro는 Claude Code를 하네스로 썼고, Terminal-Bench 2.1은 내부 인프라의 sandbox 설정을 사용했습니다. NL2Repo에서는 모델별로 Claude Code 또는 Codex 하네스를 썼고, 잠재적 cheating을 막기 위해 git clone, pip install 등 외부 정보 사용을 제한했다고 설명합니다.
이런 설명은 오히려 긍정적인 부분도 있습니다. MiniMax가 평가 환경과 제한을 어느 정도 공개했기 때문입니다. 하지만 동시에 이 수치를 독립 재현 수치처럼 받아들이면 안 된다는 뜻이기도 합니다. 코딩 에이전트 벤치마크는 모델 단독 능력과 하네스 설계가 쉽게 섞입니다. 같은 모델이라도 어떤 프롬프트, 어떤 파일 탐색 전략, 어떤 도구 제한, 어떤 retry 정책을 쓰느냐에 따라 결과가 크게 달라집니다.
특히 SWE-Bench 계열은 이제 “모델 점수표”가 아니라 “모델+하네스+평가 환경 점수표”에 가깝습니다. MiniMax M3를 팀에 도입하려면 공식 수치보다 다음 질문이 더 중요합니다. 우리 저장소에서 테스트를 제대로 실행할 수 있는가. private dependency를 다룰 수 있는가. 실패 로그를 줄이지 않고 보존하는가. 코드 리뷰 기준을 만족하는가. 보안상 터미널 권한을 어디까지 줄 것인가.
MiniMax Code와 API 접근 경로
M3는 발표와 동시에 접근 경로가 열렸습니다. 공식 발표는 MiniMax Code, Token Plan, API 서비스를 통해 바로 경험할 수 있다고 안내합니다. MiniMax Code는 M3와 함께 업데이트된 코딩 에이전트 제품입니다. MiniMax는 Agent Team이 큰 작업을 여러 단계로 나누고, Producer + Verifier adversarial 하네스 루프를 통해 생산, 반성, 수정을 반복한다고 설명합니다.
이미지 출처: MiniMax M3 제품 페이지. M3가 긴 컨텍스트, 멀티모달 입력, 코딩 에이전트 기능을 묶어 논문 재현 작업을 수행했다는 공식 사례 이미지다.
API도 열려 있습니다. 공식 API 문서는 2026년 6월 2일 확인 기준 상단에서 MiniMax-M3가 코딩과 에이전트용 frontier model로 사용 가능하다고 안내합니다. 제품 페이지의 예시는 다음처럼 MiniMax-M3 모델명을 사용합니다.
import requests
url = "https://api.minimax.io/v1/text/chatcompletion_v2"
payload = {
"model": "MiniMax-M3",
"messages": [
{"role": "user", "content": "Hello"}
]
}
headers = {"Authorization": "Bearer <token>"}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
가격과 사용량은 Token Plan 중심으로 제시됐습니다. 공식 블로그는 Plus가 월 20달러에 약 17억 M3 토큰, Max가 월 50달러에 약 51억 M3 토큰, Ultra가 월 120달러에 약 98억 M3 토큰이라고 설명합니다. API 가격은 입력 길이에 따라 갈립니다. 512K 이하 입력은 표준 요율, 512K 초과는 긴 컨텍스트 요율로 과금되며, thinking on/off와 standard/priority service tier도 선택지로 제시됐습니다.
여기서 실무자가 봐야 할 것은 “토큰이 많다”가 아닙니다. 실제 코딩 에이전트 비용은 토큰 단가, 캐시, 도구 호출 횟수, 실패 후 재시도, 긴 컨텍스트 사용 빈도가 합쳐져 결정됩니다. M3가 정말 저렴하려면 1M 컨텍스트를 넣어도 재작업을 줄이고, 실패한 시도를 오래 끌지 않으며, 팀의 CI 비용까지 고려했을 때 총 작업 비용이 내려가야 합니다.
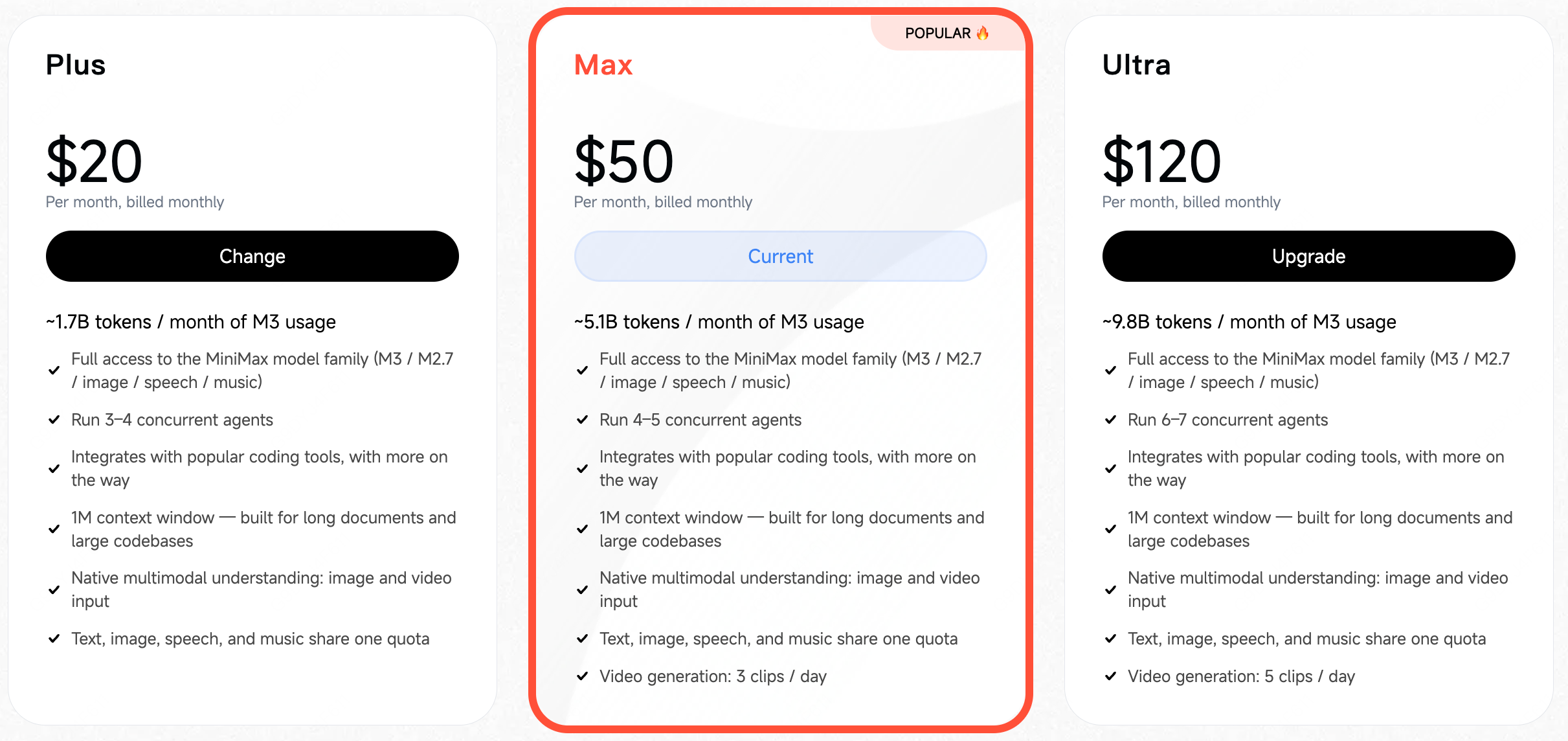
이미지 출처: MiniMax 공식 M3 발표. M3 공개와 함께 안내된 Token Plan 구조를 보여주는 공식 자료다.
오픈웨이트라는 말의 현재 상태
제목에 “오픈웨이트”가 들어가면 독자는 보통 지금 Hugging Face에서 모델을 받을 수 있다고 기대합니다. 그래서 현재 상태를 정확히 써야 합니다. MiniMax는 M3를 “open-weight model”이라고 부르지만, 2026년 6월 2일 기준으로 가중치와 기술 리포트는 아직 공개 전입니다. 공식 블로그는 앞으로 10일 안에 공개하겠다고 적었습니다.
이 차이는 작지 않습니다. API로 쓸 수 있는 모델과 로컬 또는 private cluster에 배포할 수 있는 오픈웨이트 모델은 운영 조건이 다릅니다. 가중치가 공개되면 기업은 데이터 반출, 지연시간, 커스텀 fine-tuning, 내부 보안 감사, 비용 예측을 다시 계산할 수 있습니다. 반대로 가중치가 없으면 API 정책, rate limit, 서비스 안정성, 데이터 처리 약관에 더 의존해야 합니다.
Hugging Face의 MiniMaxAI 조직 페이지도 이 점을 확인하는 참고 자료입니다. 현재 조직 카드에는 MiniMax-M2.7, M2.5, M2.1, M2 등이 최근 모델로 보이고, MiniMax 공식 웹사이트와 API 플랫폼 링크가 안내됩니다. M3가 올라오면 가장 먼저 확인할 것은 파일 형식, 라이선스, 상업적 사용 조건, context length를 로컬에서 어떻게 보장하는지, 필요한 GPU 메모리와 inference stack입니다.
“open weight”와 “open source”도 구분해야 합니다. 가중치를 공개한다고 해서 학습 데이터, 전체 학습 코드, 평가 파이프라인, 상업 사용 권한이 모두 자유롭다는 뜻은 아닙니다. MiniMax 제품 페이지는 Hugging Face와 GitHub에 공개해 private cluster deployment와 fine-tuning을 지원하겠다고 설명하지만, 실제 라이선스 문구가 나오기 전까지는 사내 도입 판단을 보류하는 편이 맞습니다.
개발자가 직접 검증할 체크리스트
M3가 공개되면 가장 좋은 검증은 거창한 리더보드 재현이 아닙니다. 우리 팀의 대표 작업 20개를 골라 같은 하네스에서 비교하는 것입니다.
첫 번째는 저장소 이해입니다. 큰 저장소에서 버그 이슈, 관련 파일, 테스트, 기존 패턴을 찾게 합니다. 1M 컨텍스트를 무작정 채우는 방식과 검색 기반으로 필요한 파일만 넣는 방식을 비교해야 합니다. 긴 컨텍스트가 장점이라면, 파일을 많이 넣었을 때 오히려 잘못된 근거를 붙잡는 일이 줄어야 합니다.
두 번째는 수정 품질입니다. 단위 테스트 통과만 보면 부족합니다. 기존 스타일을 따르는지, edge case를 깨지 않는지, 불필요한 대규모 리팩터링을 하지 않는지, 보안상 위험한 의존성을 추가하지 않는지 봐야 합니다. 코딩 모델은 “정답 코드”보다 “팀이 받아들일 수 있는 패치”를 내야 합니다.
세 번째는 장기 작업 안정성입니다. MiniMax가 강조한 147번 submission, 1,959번 tool call 같은 사례는 장기 작업에 대한 자신감입니다. 실제 검증에서는 30분, 2시간, 8시간 작업을 나눠 봐야 합니다. 오래 작업할수록 계획이 흐려지는지, 같은 시도를 반복하는지, 실패 로그를 잊는지, 비용이 예측 가능하게 증가하는지 확인해야 합니다.
네 번째는 멀티모달과 컴퓨터 사용입니다. 프론트엔드 screenshot regression, PDF 기반 요구사항 구현, 표·차트가 섞인 문서 해석 같은 작업에서 이미지 입력이 실제로 코딩 품질을 높이는지 봐야 합니다. 단순히 이미지를 설명하는 능력과, 그 설명을 코드 수정으로 연결하는 능력은 다릅니다.
다섯 번째는 데이터와 권한입니다. API 사용 시 코드, 로그, 고객 데이터가 외부로 나갈 수 있습니다. 오픈웨이트가 공개된 뒤에도 fine-tuning과 로컬 배포가 어떤 라이선스와 사용 조건을 따르는지 확인해야 합니다. 팀에서 쓸 모델이라면 성능보다 먼저 권한 경계, 감사 로그, secret masking, dependency install 제한을 설계해야 합니다.
누가 지금 써볼 만한가
당장 MiniMax M3를 API나 MiniMax Code로 시험해볼 만한 사람은 명확합니다. 첫째, 장기 코딩 에이전트 워크플로를 이미 운영 중인 개발자입니다. Claude Code, Codex CLI, Cursor, OpenCode 같은 도구를 쓰고 있고, 비용이나 context limit이 병목이었다면 M3는 비교 대상으로 넣을 가치가 있습니다.
둘째, 긴 문서와 코드가 섞인 작업을 하는 팀입니다. 논문 재현, 대형 레포 마이그레이션, SDK 문서 업데이트, 테스트 리팩터링처럼 “파일 몇 개”로 끝나지 않는 업무가 여기에 들어갑니다. 1M 컨텍스트가 실제로 도움이 되는지 보려면 이런 작업이 더 적합합니다.
셋째, 오픈웨이트 모델을 사내 인프라에 올리고 싶은 팀입니다. 다만 이 경우는 지금 바로 도입이 아니라 대기 목록에 가깝습니다. 가중치와 기술 리포트, 라이선스가 공개된 뒤에야 본격 검토가 가능합니다. 지금 할 일은 벤치마크 하네스와 대표 작업 세트를 미리 준비하는 것입니다.
반대로 단순 자동완성, 짧은 스크립트 작성, 일상 질문 답변이 주 용도라면 M3의 장점은 과할 수 있습니다. 1M 컨텍스트와 장기 에이전트 성능은 비용과 통제를 같이 요구합니다. 작은 작업에는 빠르고 안정적인 기존 모델이 더 나을 수 있습니다.
관전 포인트
앞으로 10일이 중요합니다. MiniMax가 예고한 기술 리포트와 가중치가 실제로 공개되면 세 가지를 봐야 합니다.
첫째, 재현성입니다. 공식 벤치마크 수치가 외부 하네스에서 어느 정도 유지되는지 봐야 합니다. 특히 SWE-Bench Pro, Terminal-Bench, MCP Atlas처럼 도구 사용과 평가 환경에 민감한 지표는 독립 재현이 중요합니다.
둘째, 라이선스입니다. 오픈웨이트라는 이름이 실제 기업 사용에 얼마나 열려 있는지 확인해야 합니다. 상업 사용 제한, fine-tuning 허용 범위, 모델 출력물 권리, 재배포 조건이 도입 판단을 좌우합니다.
셋째, 경제성입니다. MiniMax는 Token Plan을 강하게 밀고 있습니다. 많은 토큰을 제공하는 것은 매력적이지만, 장기 에이전트는 토큰을 빨리 태웁니다. 비용 계산은 “월 구독료 대비 토큰 수”가 아니라 “성공한 PR 하나당 총 비용”으로 해야 합니다.
M3가 의미 있는 이유는 오픈 모델 경쟁의 질문을 바꿨기 때문입니다. 이제 질문은 “이 모델이 몇 B인가”가 아니라 “큰 작업을 오래, 싸게, 검증 가능하게 끝낼 수 있는가”입니다. MiniMax가 그 답을 정말 제시했는지는 아직 외부 검증이 필요합니다. 다만 M3 발표가 코딩 모델 경쟁의 다음 기준을 분명히 보여준 것은 맞습니다. 긴 컨텍스트, 도구 사용, 멀티모달, 하네스 설계가 한 묶음으로 평가되는 시대입니다.
출처와 더 읽을 거리
- MiniMax 공식 발표: MiniMax M3 — M3 공개일, MSA 설명, 코딩·에이전트 벤치마크, Token Plan, 가중치 공개 예고, 평가 방법론을 확인한 1차 자료다.
- MiniMax M3 제품 페이지 — API 접근 경로, 1M 컨텍스트 보장, BrowseComp·PostTrainBench 사례, MiniMax Code와 외부 코딩 도구 연동 설명을 확인할 수 있는 공식 제품 자료다.
- MiniMax API Overview — MiniMax-M3 API 사용 가능 여부와 MiniMax API 문서 구조를 확인할 수 있는 공식 개발자 문서다.
- MiniMaxAI Hugging Face 조직 페이지 — 2026년 6월 2일 기준 공개 모델 목록과 M3 가중치 공개 전 상태를 확인하기 위한 공식 배포 채널이다.
- Reddit r/LocalLLaMA의 MiniMax M3 토론 — 커뮤니티가 1M 컨텍스트의 실효성, API 접근성, 오픈웨이트 공개 전 검증 필요성을 어떻게 보고 있는지 참고할 수 있는 반응 원문이다.