핵심 요약
OpenAI가 로봇을 다시 전면에 꺼냈다. 2026년 5월 31일 Sam Altman은 X에서 OpenAI Robotics가 풀스택 하드웨어, 운영, 시스템, 머신러닝 엔지니어를 찾고 있다고 밝혔다. 공개적으로 확인 가능한 원문은 Sam Altman의 X 게시물이며, 여러 보도는 이 글에서 Altman이 “AI가 물리 세계에서 사람을 도울 수 있어야 한다”는 취지로 단기와 장기 목표를 나눴다고 전했다. 단기적으로는 미래 인프라를 짓는 숙련 노동자를 돕는 로봇, 장기적으로는 누구나 필요한 일을 시킬 수 있는 개인 로봇이라는 그림이다.
하지만 이 뉴스를 “OpenAI가 집안일 로봇을 곧 판다”로 읽으면 핵심을 놓친다. 공식 채용 공고를 보면 OpenAI가 지금 가장 세게 뽑는 것은 예쁜 휴머노이드 외형 디자이너가 아니라 시뮬레이션 환경, 시뮬레이션 현실성, 대규모 데이터 시스템, 펌웨어, 로봇 소프트웨어, 평가 자동화 인력이다. 즉 첫 번째 전장은 완제품 로봇 매장이 아니라 로봇이 움직이기 전에 세상을 시험하는 데이터와 시뮬레이션 공장이다.
이 글은 개발자, AI 업계·연구 관심층, 비즈니스·투자 관심층을 위한 글이다. 일반 독자에게 중요한 질문도 같다. OpenAI가 말하는 개인 로봇은 언제쯤 현실적인가. ChatGPT를 만든 회사가 왜 다시 로봇으로 돌아오는가. 그리고 NVIDIA, Figure, Tesla, Google DeepMind가 이미 뛰고 있는 물리 AI 경쟁에서 OpenAI는 무엇을 다르게 보려는가.
OpenAI Robotics의 핵심을 로봇 제품이 아닌 시뮬레이션·검증·학습 루프로 요약한 인포그래픽. (이미지: 본 블로그 제작)
이번 신호가 단순 채용 공고 이상인 이유
OpenAI의 공식 채용 페이지는 로보틱스 팀의 목표를 반복해서 같은 문장으로 설명한다. “general-purpose robotics”를 열고, 동적 현실 환경에서 AGI급 지능으로 나아가며, 모델 스택 전체에서 하드웨어와 소프트웨어를 통합한다는 표현이다. 이 문구만 보면 추상적이다. 그런데 세부 직무를 보면 방향이 또렷해진다.
Simulation Environments Engineer 공고는 연구자가 로봇 작업 환경을 빠르게 설명하고, 시각화하고, 생성하고, 검증할 수 있는 도구와 인프라를 만든다고 설명한다. Isaac, Unity, Unreal, Omniverse 같은 엔진·저장소에서 환경을 가져오고, 절차적 생성과 도메인 랜덤화로 다양한 시각·물리·운동 조건을 만들며, CI/CD와 대규모 시뮬레이션 팜, 모델 평가 파이프라인에 연결하는 역할이다.
Simulation Realism Engineer 공고는 더 직접적이다. 목표는 시뮬레이션을 “정량적으로 실제처럼” 만드는 것이다. 물리, 센서, 렌더링에서 sim-to-real 격차를 줄이고, 접촉·마찰·질량·밀도·솔버 설정을 실제 측정값에 맞춰 조정하며, MuJoCo, PhysX, Isaac Sim 같은 엔진을 평가·통합한다고 되어 있다. Simulation Applications Engineer는 이 시뮬레이션을 모델 학습, 평가, hardware-in-the-loop 검증, presubmit 체크, 자동 대시보드, 수만 개 규모의 동시 rollout으로 연결한다.
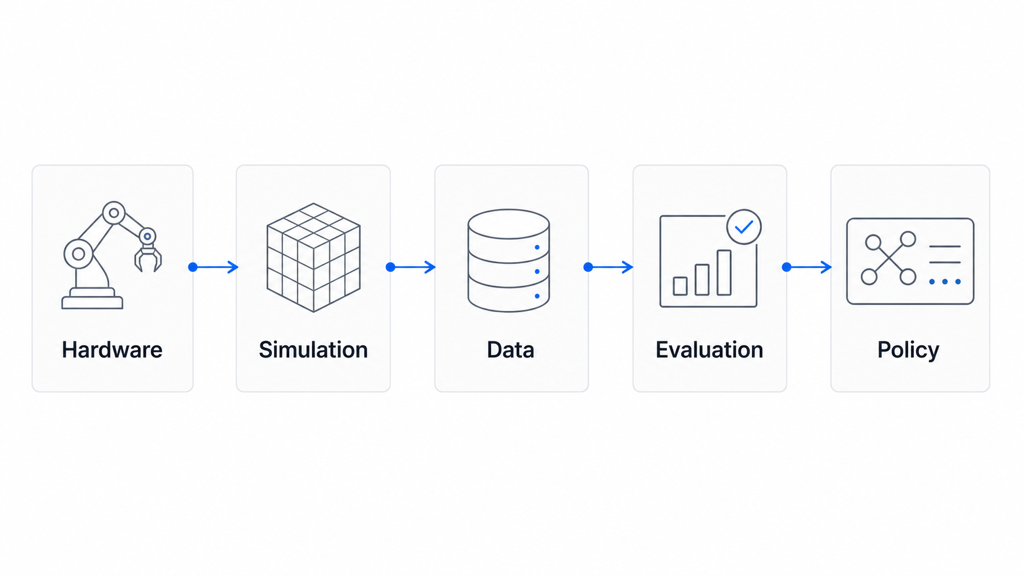
이 조합은 “로봇 연구팀을 다시 만들었다”보다 훨씬 구체적이다. OpenAI는 로봇 몸체만 고르는 단계가 아니라, 로봇 정책을 학습하고 검증하는 생산 공정을 만들고 있다. 대규모 언어모델에서 웹 문서와 코드가 맡았던 역할을, 로보틱스에서는 시뮬레이션 환경과 실제 로봇 데이터가 맡아야 한다. OpenAI가 다시 로봇을 보는 이유도 여기에 있다.
OpenAI는 왜 한 번 접었던 로봇으로 돌아오나
OpenAI는 로보틱스가 처음인 회사가 아니다. 2019년 OpenAI는 사람 손처럼 생긴 로봇 손으로 Rubik’s Cube를 조작하는 연구를 공개했다. 당시 핵심은 Automatic Domain Randomization이었다. 실제 세계의 마찰, 탄성, 동역학을 정확히 모델링하기 어렵기 때문에, 시뮬레이션 안에서 조건을 계속 바꿔가며 정책이 낯선 현실에도 버티게 만드는 접근이었다.
그 연구는 멋진 데모였지만 한계도 분명했다. OpenAI 스스로도 어려운 scramble에서는 성공률이 20%, 단순한 경우에도 60%라고 밝혔다. 로봇 AI는 화면 안의 텍스트 생성과 다르다. 물체가 미끄러지고, 센서가 흔들리고, 모터가 열을 받고, 카메라 시야 밖으로 손이 나가고, 실패가 물리적 위험으로 이어진다. 그래서 2020년 전후 OpenAI가 로보틱스 팀을 접었다는 보도가 나왔고, 업계에서는 데이터와 운영 비용이 큰 병목으로 해석했다.
2026년의 재가동은 그때의 반복이 아니다. 지금 OpenAI에는 ChatGPT 이후 쌓인 멀티모달 모델, 대규모 추론 인프라, 에이전트형 도구 사용 경험, Sora 계열의 비디오·세계 모델 연구 기반이 있다. 공개 채용 공고에서 World Simulation이라는 단어가 직접 나오지는 않지만, 시뮬레이션 환경 생성, 현실성 측정, 대규모 rollout, 하드웨어-in-the-loop 검증을 묶어 보면 방향은 분명하다. 로봇이 실제 공간에서 행동하기 전에, 가능한 장면을 충분히 만들어 보고 평가하는 체계를 키우겠다는 것이다.
이 점에서 OpenAI Robotics는 ChatGPT의 “다음 인터페이스”라기보다 모델 회사가 물리 세계 데이터를 얻기 위한 새로운 연구·제품 조직에 가깝다. 개인 로봇은 최종 상상도다. 그 앞에는 데이터 수집실, 텔레오퍼레이션, 시뮬레이션 팜, 센서 보정, 펌웨어 안정화, 평가 벤치마크, 안전 정지 설계가 길게 놓여 있다.
이미지 출처: OpenAI 공식 블로그, "Solving Rubik's Cube with a robot hand". OpenAI가 2019년 시뮬레이션 기반 로봇 손 연구에서 이미 sim-to-real 문제를 다뤘다는 맥락을 보여준다.
World Simulation이 로봇 경쟁의 중심이 되는 이유
로봇 학습의 가장 큰 병목은 좋은 모델 이름이 아니라 데이터다. LLM은 웹 문서, 코드, 책, 대화 로그에서 방대한 학습 신호를 얻었다. 로봇은 훨씬 까다롭다. 컵을 집는 행동 하나도 컵 재질, 무게, 손잡이 방향, 조명, 테이블 높이, 로봇 팔의 관절 한계에 따라 결과가 달라진다. 집안일처럼 비정형 환경으로 가면 변수가 폭발한다.
그래서 로봇 연구에서 world model과 world simulation이 중요해진다. Microsoft Research가 2026년 4월 공개한 로봇 학습용 월드 모델 서베이는 월드 모델을 “행동에 따라 환경이 어떻게 변하는지 예측하는 표현”으로 정리한다. 이 모델은 정책 학습, 계획, 시뮬레이션, 평가, 데이터 생성에 쓰인다. 2026년 3월 arXiv에 올라온 Interactive World Simulator 논문도 같은 방향을 보여준다. 저자들은 행동 조건부 비디오 예측 기반 월드 모델이 로봇 정책 학습과 평가에 유망하지만, 기존 방식은 느리고 장기 물리 일관성이 약하다고 지적한 뒤, 단일 RTX 4090에서 15FPS로 10분 넘게 안정적인 상호작용을 생성했다고 보고했다.
OpenAI 채용 공고의 언어는 이 연구 흐름과 맞물린다. 시뮬레이션 환경을 많이 만들고, 현실성 지표를 세우고, 자동 평가를 돌리고, 대규모 멀티모달 데이터 인프라를 키우는 이유는 하나다. 현실에서 모든 실패를 직접 겪기 전에, 가상 환경에서 충분히 흔들어 보는 것이다. 이 과정이 잘 되면 로봇은 실제 데이터만 기다리는 기계가 아니라, 상상한 상황에서 먼저 연습하고 현실에서 보정하는 시스템이 된다.
물론 “상상”이 만능은 아니다. 로봇은 언어모델보다 훨씬 냉정하게 실패한다. 시뮬레이션에서 잘 잡은 물체가 현실에서는 미끄러질 수 있고, 영상 모델이 그럴듯하게 만든 장면이 실제 접촉력과는 맞지 않을 수 있다. 그래서 OpenAI가 Simulation Realism, hardware-in-the-loop, data collection lab, firmware를 동시에 뽑는 것이다. 월드 모델만으로는 부족하고, 실제 하드웨어와 계속 맞물려야 한다.
개인 로봇보다 먼저 올 것은 산업용 보조 로봇이다
Altman이 말한 장기 그림은 개인 로봇이다. 하지만 단기 목표는 훨씬 현실적이다. 보도들이 전한 표현대로라면 OpenAI는 먼저 “미래 인프라를 짓는 숙련 노동자”를 돕는 로봇에 집중한다. 이 순서는 중요하다. 집 안은 로봇에게 매우 어려운 환경이다. 물건 종류가 제각각이고, 사람과 아이, 반려동물, 좁은 통로, 예외 상황이 많다. 사용자는 안전 기준도 높고 가격 민감도도 크다.
반대로 공장, 데이터센터, 물류, 실험실, 건설 보조 같은 환경은 상대적으로 작업 범위를 좁힐 수 있다. 로봇이 해야 할 행동을 제한하고, 작업 공간을 정리하고, 안전 구역을 만들고, 실패 로그를 모으기 쉽다. OpenAI가 처음부터 가정용 만능 로봇을 팔기보다 “숙련 노동자 보조”를 말하는 것은 기술적으로도 사업적으로도 자연스럽다.
이 흐름은 경쟁사와도 이어진다. Figure는 2024년 2월 OpenAI Startup Fund, Microsoft, NVIDIA, Jeff Bezos 등이 참여한 6억 7,500만 달러 규모 투자를 발표했고, OpenAI와 휴머노이드용 차세대 AI 모델 개발 협력도 맺었다. 이후 Figure, Tesla Optimus, 1X, Agility Robotics, Google DeepMind Gemini Robotics, NVIDIA Isaac GR00T가 모두 물리 AI를 향해 움직이고 있다. OpenAI의 재진입은 갑작스러운 변덕이 아니라, 생성 AI 회사들이 다음 데이터와 인터페이스를 물리 세계에서 찾기 시작했다는 신호다.
다만 개인 로봇은 여전히 먼 목표다. 배터리, 모터, 손 조작, 안전 인증, 가격, 유지보수, 소음, 프라이버시, 집안 촬영 데이터 처리까지 풀어야 할 문제가 많다. 특히 “개인 로봇”은 집안 카메라와 마이크, 위치 정보, 생활 패턴을 지속적으로 다룰 수밖에 없다. ChatGPT의 개인정보 논쟁보다 더 민감한 영역이다. OpenAI가 소비자 로봇으로 간다면 모델 성능뿐 아니라 로컬 처리, 데이터 보존, 녹화 제어, 긴급 정지, 책임 소재를 제품 수준에서 설명해야 한다.

개인 로봇 상용화 전에 확인해야 할 안전·개인정보·가격·유지보수·작업 성공률 체크포인트 정리. (이미지: 본 블로그 제작)
개발자와 기업이 지금 봐야 할 포인트
첫째, OpenAI Robotics를 “하드웨어 스타트업 진입”으로만 보지 말아야 한다. 공식 채용 공고의 무게중심은 시뮬레이션, 데이터, 평가, 펌웨어, 분산 시스템이다. 로봇 몸체는 바뀔 수 있지만, 데이터 파이프라인과 평가 체계는 OpenAI의 핵심 자산이 될 가능성이 크다.
둘째, World Simulation은 로봇만의 이야기가 아니다. 자율주행, 스마트팩토리, 산업 안전, 데이터센터 운영, 의료·실험실 자동화도 모두 “행동하기 전에 예측하고 검증하는 AI”가 필요하다. OpenAI가 이 영역에서 성과를 내면 ChatGPT API처럼 로봇용 모델 API, 시뮬레이션 평가 도구, 하드웨어 파트너 생태계로 확장될 수 있다.
셋째, 안전과 거버넌스가 더 중요해진다. 화면 속 오류는 되돌릴 수 있지만, 로봇 오류는 실제 공간에서 사람과 장비를 건드린다. 기업이 물리 AI를 도입할 때는 모델 벤치마크보다 운영 조건을 먼저 봐야 한다. 실패 시 정지 방식, 로그 보존, 사람이 개입하는 권한, 작업 구역 분리, 시뮬레이션과 현실 성능 차이 측정이 필수다. AI 모델 평가를 도입 의사결정으로 연결하는 법은 앞서 정리한 OpenAI 제3자 평가 플레이북 글과도 맞닿아 있다. 로봇에서는 하네스와 평가 조건의 차이가 화면 점수보다 훨씬 큰 안전 차이로 이어질 수 있다.
넷째, 한국 기업에는 기회와 압박이 동시에 온다. 제조·물류·반도체·조선·건설 현장은 숙련 노동자 보조 로봇의 초기 적용처가 될 수 있다. 하지만 OpenAI, NVIDIA, Google, Tesla가 데이터·시뮬레이션·모델 스택을 장악하면 국내 로봇 기업은 하드웨어만 만드는 회사로 밀릴 위험도 있다. 지금부터 자체 데이터 포맷, 시뮬레이터 호환성, 안전 평가 절차, 모델 교체 가능성을 챙겨야 한다.
결론: OpenAI의 로봇 재가동은 ChatGPT의 몸을 만드는 일이 아니다
OpenAI Robotics의 재가동을 “ChatGPT가 로봇 몸을 얻는다”로만 표현하면 너무 단순하다. 더 정확히는 OpenAI가 디지털 모델 회사에서 물리 세계를 다루는 모델·데이터·평가 회사로 확장하려는 움직임이다. 개인 로봇은 매력적인 헤드라인이지만, 현재 공식 채용 신호가 보여주는 실전 과제는 시뮬레이션 환경, 현실성 검증, 데이터 수집, 펌웨어, 대규모 평가 자동화다.
그래서 이번 뉴스의 관전 포인트는 “언제 우리 집에 OpenAI 로봇이 오나”가 아니다. 더 중요한 질문은 “OpenAI가 로봇이 배우는 세계를 누가 만들고, 누가 평가하고, 누가 업데이트하는가”라는 문제에 뛰어들었다는 점이다. LLM 시대에는 텍스트와 코드가 모델의 먹이였다. 로봇 시대에는 현실의 움직임, 실패, 접촉, 위험이 데이터가 된다. OpenAI가 그 데이터를 안전하고 확장 가능한 방식으로 다룰 수 있다면, 다음 경쟁은 챗봇이 아니라 현실을 움직이는 AI에서 벌어질 것이다.
출처와 더 읽을 거리
- Sam Altman X 원문: OpenAI Robotics 채용과 개인 로봇 비전을 직접 언급한 원문 링크다. X 페이지 본문은 비로그인 환경에서 보이지 않을 수 있어, 본문에서는 보도와 공식 채용 공고로 교차 확인했다.
- OpenAI Careers: Simulation Environments Engineer: OpenAI Robotics가 시뮬레이션 환경 생성, 도메인 랜덤화, CI/CD와 모델 평가 파이프라인을 중시한다는 점을 확인할 수 있는 공식 채용 공고다.
- OpenAI Careers: Simulation Realism Engineer: sim-to-real 격차, 물리·센서·렌더링 현실성, MuJoCo·PhysX·Isaac Sim 같은 엔진 평가를 OpenAI가 핵심 업무로 보고 있음을 보여주는 자료다.
- OpenAI Careers: Simulation Applications Engineer: 시뮬레이션을 모델 학습, 자동 평가, hardware-in-the-loop 검증, 대규모 rollout 인프라로 연결하려는 운영 방향을 확인할 수 있다.
- OpenAI Careers: Robotics Software Engineer: 로봇 데이터 수집 랩, 다양한 하드웨어 통합, 로봇 제어 인터페이스와 평가 자동화가 실제 채용 범위에 들어 있음을 보여준다.
- OpenAI Careers: Firmware Engineer, Robotics: OpenAI Robotics가 모델 연구뿐 아니라 보드 bring-up, 센서 통합, 저수준 펌웨어까지 직접 다루려 한다는 점을 확인할 수 있는 공식 자료다.
- OpenAI Careers: Software Engineer, Distributed Data Systems – Robotics: 대규모 멀티모달 학습·평가를 위한 분산 데이터 인프라가 로보틱스 조직의 핵심 기반임을 보여준다.
- OpenAI 공식 블로그: Solving Rubik’s Cube with a robot hand: 2019년 OpenAI 로봇 손 연구와 Automatic Domain Randomization, 시뮬레이션 기반 학습의 역사적 맥락을 확인할 수 있다.
- Microsoft Research: World Model for Robot Learning: A Comprehensive Survey: 로봇 학습에서 월드 모델이 정책 학습, 계획, 평가, 데이터 생성에 어떻게 쓰이는지 정리한 2026년 서베이다.
- arXiv: Interactive World Simulator for Robot Policy Training and Evaluation: 행동 조건부 비디오 예측 기반 월드 모델이 로봇 정책 학습과 평가에 어떻게 쓰일 수 있는지 실험적으로 보여주는 논문이다.
- Figure AI PRNewswire 발표: 2024년 Figure의 6억 7,500만 달러 투자와 OpenAI 협력 발표를 통해 OpenAI가 로봇 생태계와 연결돼 온 배경을 확인할 수 있다.