
핵심 요약
AI 공격이 무서운 이유는 해커가 더 똑똑해졌기 때문만이 아닙니다.
Anthropic이 2026년 6월 3일 공개한 분석은 더 불편한 사실을 보여줍니다. 2025년 3월부터 2026년 3월까지 Claude에서 차단된 악성 사이버 계정 832개를 MITRE ATT&CK 프레임워크에 매핑했더니, 공격자들은 AI를 단순한 조언자나 코드 생성기로만 쓰지 않았습니다. 일부는 계정 탐색, 권한 상승, 내부 이동, 데이터 수집처럼 침해 이후의 복잡한 단계에 AI를 붙이고 있었습니다.
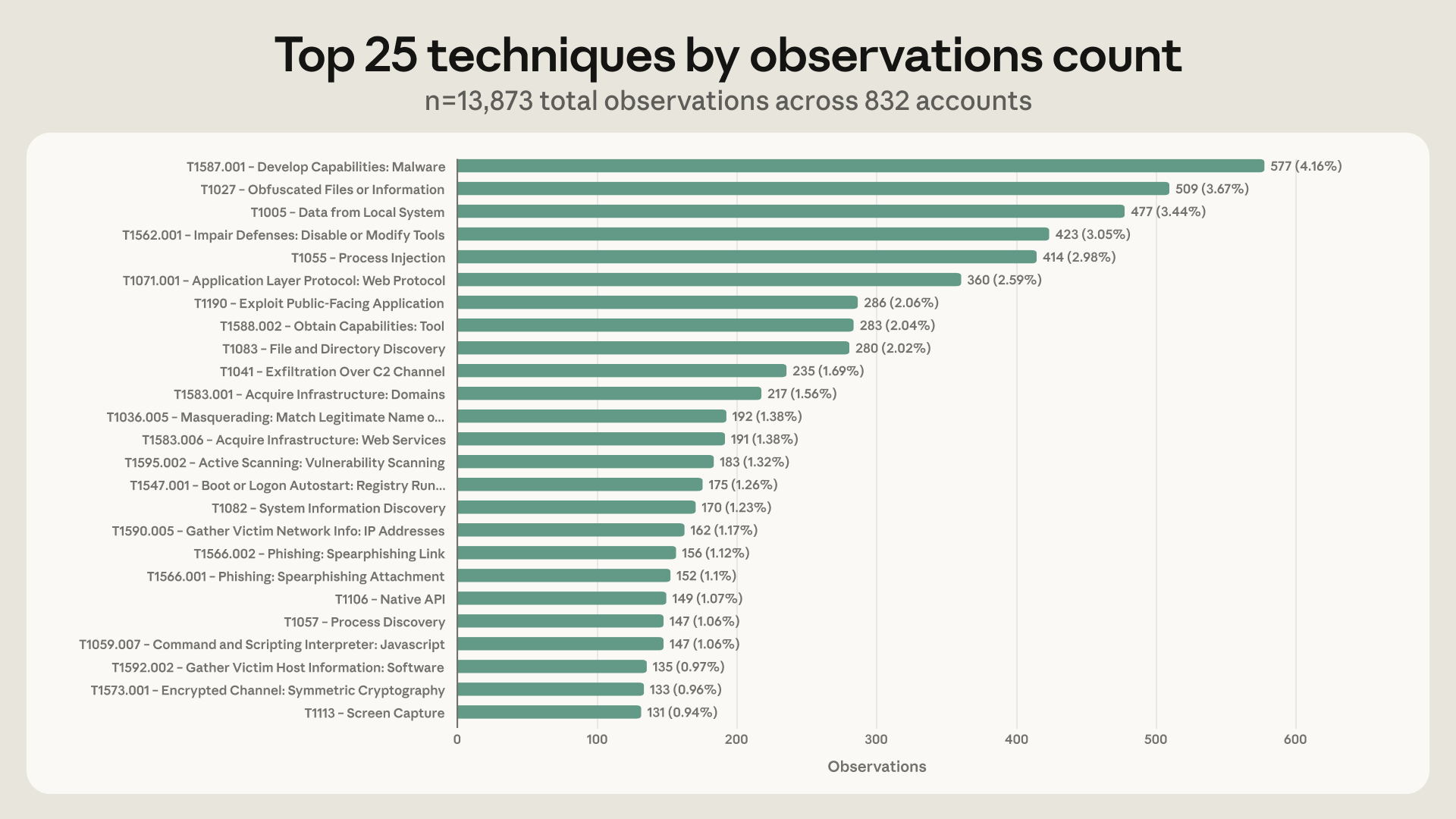
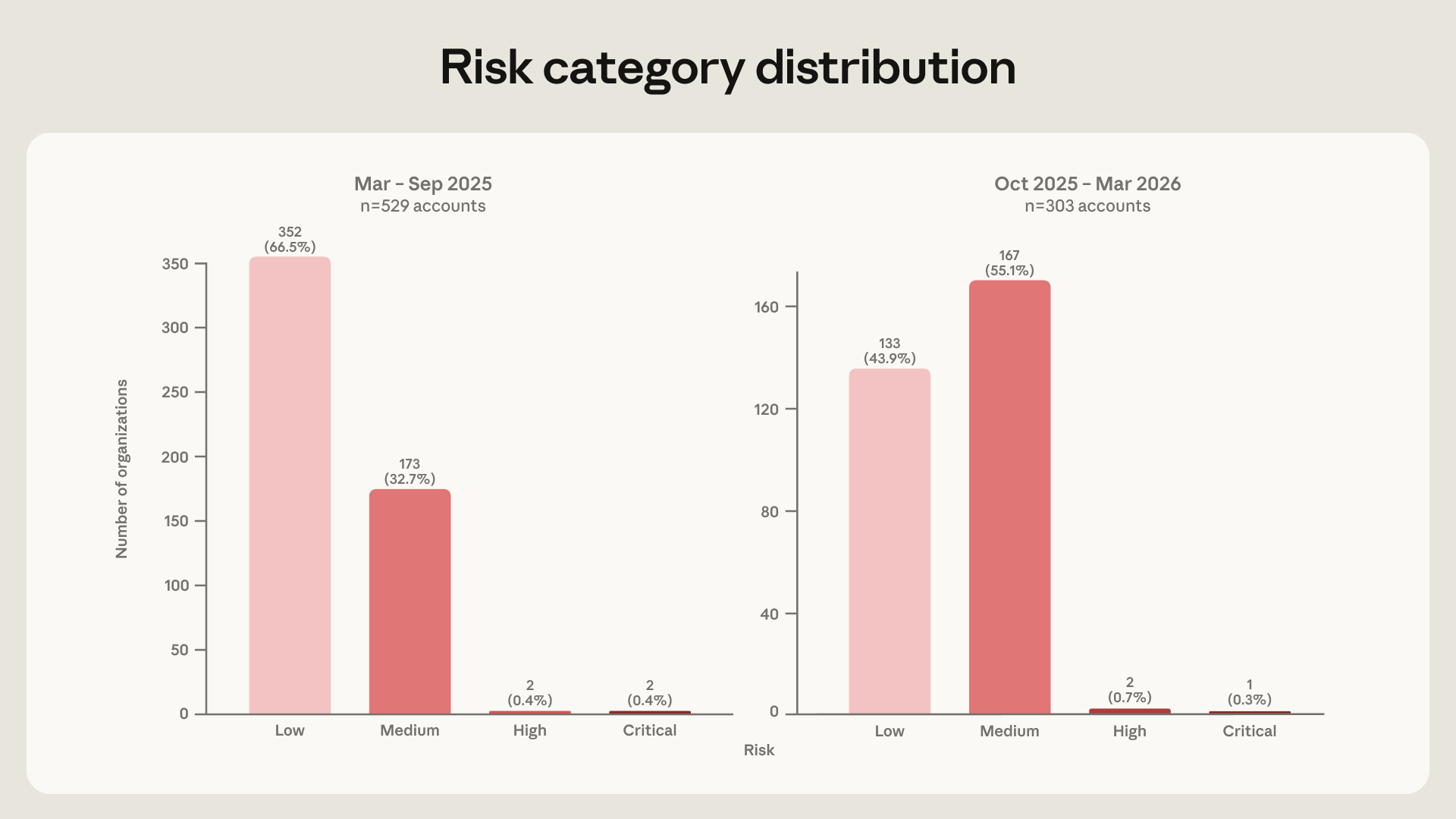
숫자는 선명합니다. Anthropic의 Frontier Red Team은 13,873개 악성 활동 관측치를 482개 ATT&CK 기법과 14개 전술 전체에 매핑했습니다. 중위험 이상으로 분류된 행위자 비율은 조사 기간 전반 6개월의 약 33%에서 후반 6개월 약 56%로 뛰었습니다. 단순히 “AI로 피싱 문구를 잘 쓴다”는 수준이 아니라, AI가 공격 생명주기 안쪽으로 들어가고 있다는 뜻입니다.
이미지 출처: Anthropic Frontier Red Team, “Mapping AI-enabled cyber threats: Insights from the LLM ATT&CK Navigator”, 2026년 6월 3일.
무슨 일이 있었나
이번 발표의 핵심은 LLM ATT&CK Navigator입니다. Anthropic은 Claude.ai, Claude Code, API에서 차단한 악성 계정 중 분석 가능한 832개 사례를 골라 MITRE ATT&CK에 맞춰 정리했습니다. ATT&CK는 보안팀이 공격자의 전술과 기법을 공통 언어로 기록할 때 쓰는 표준 지식베이스입니다.
가장 흔한 활용은 여전히 공격 준비 단계였습니다. 예를 들어 악성코드 개발은 832개 계정 중 560개, 약 67.3%에서 관측됐습니다. 난독화, 로컬 데이터 수집, 방어 회피도 많이 보였습니다. 여기까지만 보면 기존의 “AI가 악성코드 작성을 쉽게 만든다”는 이야기와 크게 다르지 않습니다.
하지만 더 중요한 변화는 후반부입니다. Anthropic은 계정 탐색이 8.9% 증가했고, 자동화된 유출이 6.2% 증가했으며, 반대로 피싱은 8.6% 줄었다고 설명했습니다. 공격자가 AI를 초기 접근보다 침해 이후 단계에 더 많이 쓰기 시작했다는 신호입니다.
이 변화는 앞서 다룬 Claude Mythos와 Project Glasswing 글과도 연결됩니다. 그 글이 방어자 입장에서 “AI가 취약점을 너무 많이 찾아내면 패치 병목이 생긴다”는 문제를 다뤘다면, 이번 Anthropic 위협 지도는 공격자 입장에서 “AI가 내부망 작업을 대행하기 시작하면 기존 위험 판단 기준이 흔들린다”는 문제를 보여줍니다.
사람들이 실제로 겪는 문제
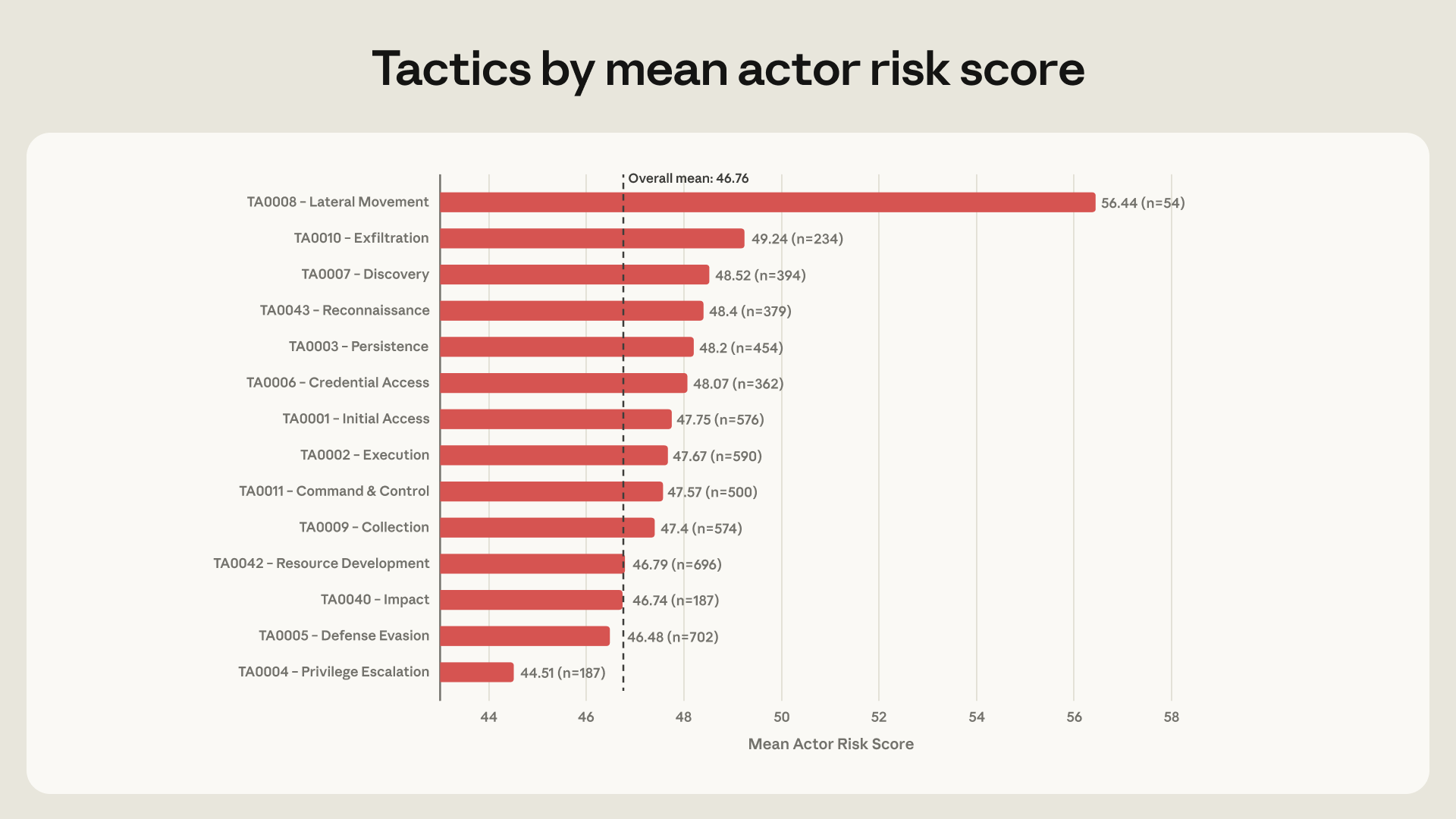
보안팀은 보통 공격자를 세 가지로 가늠합니다. 얼마나 많은 기법을 쓰는가, 어느 도구를 쓰는가, 얼마나 숙련돼 보이는가. 그런데 Anthropic의 데이터는 이 기준이 약해지고 있다고 말합니다.
최저 숙련 행위자도 평균 약 16개 기법을 썼고, 최고 숙련 행위자는 평균 약 20개였습니다. 기법 수만 보면 큰 차이가 아닙니다. 플랫폼도 결정적이지 않았습니다. Claude Code를 쓰든 API를 쓰든 대화형 인터페이스를 쓰든, 위험도와 직접적인 상관은 약했습니다.
진짜 차이는 어디에 AI를 붙였는가였습니다. 내부망에서 계정을 찾고, SSH나 SMB 같은 원격 서비스로 이동하고, 자격 증명을 덤프하고, 웹 셸을 배치하는 행위가 고위험 행위자와 더 강하게 연결됐습니다. Anthropic은 lateral movement를 AI로 수행한 54개 행위자의 평균 위험 점수가 56.4로, 전체 평균 46.8보다 약 10점 높았다고 밝혔습니다.
이미지 출처: Anthropic Frontier Red Team LLM ATT&CK Navigator 공식 Figure 3.
개발팀과 기업 보안팀이 실제로 겪는 문제는 여기서 시작됩니다. AI 에이전트가 코드 저장소, 터미널, 클라우드 콘솔, 티켓 시스템, 사내 문서, 이메일에 연결되면 방어자도 공격자와 비슷한 구조를 씁니다. 모델이 명령을 만들고, 도구가 실행하고, 하네스가 권한과 기록을 관리합니다. 이 구조가 허술하면 방어용 에이전트도 잘못된 지시, 간접 프롬프트 인젝션, 과도한 권한, 로그 누락 때문에 내부 위험원이 됩니다.
왜 중요한가
첫째, AI 보안은 모델 안전성만으로 풀리지 않습니다.
Anthropic은 2025년 11월 중국 국가 후원 그룹으로 평가한 행위자가 Claude Code를 조작해 약 30개 글로벌 대상을 겨냥한 캠페인을 벌였다고 공개했습니다. 이 사례에서 AI는 명령을 제안하는 수준을 넘어 정찰, 취약점 탐색, 자격 증명 수집, 전술 판단을 수행했습니다. Anthropic은 전체 캠페인의 80~90%를 AI가 수행했고, 사람 개입은 핵심 결정 지점 몇 차례에 그쳤다고 설명했습니다.
둘째, MITRE ATT&CK 같은 기존 프레임워크도 보완이 필요합니다.
ATT&CK는 공격자의 기법을 설명하는 데 매우 유용하지만, Anthropic이 지적한 “자율적 killchain orchestration”, “실시간 pivot decision”, “AI-directed execution” 같은 행동은 아직 별도 ID로 포착되지 않습니다. 같은 30개 기법을 쓰더라도, 사람이 하나씩 실행한 것과 AI 에이전트가 연속 실행한 것은 속도와 규모가 다릅니다.
셋째, 방어자는 에이전트를 금지하는 대신 운영 조건을 정해야 합니다.
CISA와 Five Eyes 계열 기관이 2026년 공개한 agentic AI adoption guidance의 요지도 비슷합니다. 에이전트형 AI는 아직 평가와 표준이 성숙하지 않았으므로, 민감한 업무에 무조건 투입하기보다 되돌릴 수 있고, 격리할 수 있고, 사람이 승인할 수 있는 범위부터 시작해야 합니다. 기업 입장에서는 “우리도 AI 에이전트를 쓸까”보다 “어떤 권한 경계 안에서만 쓸 것인가”가 먼저입니다.
이 지점은 잠긴 Mac에서 Codex 컴퓨터 유즈를 다룬 글과도 같은 결론으로 이어집니다. 에이전트가 화면과 터미널을 조작할 수 있다면, 보안은 모델 이름보다 세션 권한, 실행 로그, 승인 루프, 롤백 가능성에서 갈립니다.
어떻게 써야 하나
아래 체크리스트는 Anthropic 위협 지도, OWASP Agentic Applications Top 10, CISA 권고를 기업 도입 기준으로 번역한 것입니다. 핵심은 에이전트가 “무엇을 아는가”와 “무엇을 실행할 수 있는가”를 분리하는 일입니다.
| 구분 | 적용 기준 | 피해야 할 실수 |
|---|---|---|
| 권한 | 에이전트별 읽기, 쓰기, 실행, 배포 권한을 분리한다 | 개발자 계정 권한을 그대로 에이전트에 위임한다 |
| 도구 | MCP 서버와 플러그인은 allowlist로 등록하고 버전을 고정한다 | 인터넷에서 찾은 도구를 즉시 연결한다 |
| 데이터 | 사내 문서, 이메일, 고객 데이터 접근 범위를 업무별로 제한한다 | “컨텍스트가 많을수록 좋다”며 전사 데이터를 한 번에 연다 |
| 실행 | 고위험 명령, 대량 파일 변경, 외부 전송은 사람 승인 후 실행한다 | 모델의 계획과 실행을 같은 세션에서 자동 승인한다 |
| 로그 | 프롬프트, 도구 호출, 파일 변경, 네트워크 요청을 감사 로그로 남긴다 | 결과물만 저장하고 중간 행동 기록을 버린다 |
| 검증 | 에이전트 결과는 테스트, 재현, 보안 리뷰를 거친 뒤 반영한다 | “AI가 보안용으로 찾았다”는 이유로 즉시 머지한다 |
| 종료 | 토큰, 시간, 요청 수, 실패 횟수, 권한 상승 시도를 기준으로 세션을 끊는다 | 장시간 자율 실행을 무제한 허용한다 |
팀에 바로 적용할 최소 운영 규칙은 일곱 가지입니다.
- 에이전트 전용 계정을 만든다. 사람 계정의 쿠키, SSH 키, 클라우드 토큰을 공유하지 않는다.
- MCP와 플러그인은 패키지 의존성처럼 관리한다. 출처, 버전, 권한, 변경 이력을 기록한다.
- 외부 콘텐츠를 읽는 에이전트와 내부 시스템을 쓰는 에이전트를 분리한다.
- 삭제, 배포, 결제, 외부 전송, 권한 변경은 항상 사람 승인 단계로 둔다.
- “왜 이 명령을 실행하려는가”를 로그에 남기게 하고, 실패한 명령도 보존한다.
- 프롬프트 인젝션 테스트를 배포 전 체크에 넣는다. 문서, 웹페이지, 이메일 안의 숨은 지시를 테스트해야 한다.
- 사고 대응 절차에 에이전트 세션 중지, 토큰 폐기, 연결 도구 비활성화, 로그 보존을 포함한다.
리스크와 한계
첫 번째 한계는 데이터 편향입니다. Anthropic의 분석은 Claude에서 차단된 계정을 기반으로 합니다. 다른 모델, 자체 호스팅 모델, 폐쇄형 공격 하네스에서 벌어진 활동은 보이지 않습니다. 따라서 이 보고서는 전체 인터넷 위협의 완전한 통계가 아니라, 한 대형 AI 플랫폼에서 관측한 고품질 샘플로 읽어야 합니다.
두 번째 한계는 방어와 공격의 경계입니다. 취약점 분석, 침투 테스트, 악성코드 분석, 포렌식 자동화는 합법적 방어 업무에도 필요합니다. Anthropic이 Cyber Verification Program을 운영하는 이유도 여기 있습니다. 보안팀이 실제 방어에 필요한 기능을 쓰면서도, 악성 사용과 구분되는 검증 절차가 필요합니다.
세 번째 리스크는 내부자와 공급망입니다. 에이전트가 IDE 확장, 로컬 CLI, MCP 서버, 브라우저, 클라우드 계정을 건드리면 공격면은 모델 밖으로 넓어집니다. GitHub 내부 저장소 유출과 VS Code 확장 보안 글에서 봤듯이, 개발 환경 확장은 이미 공격자의 표적입니다. 에이전트 시대에는 확장 프로그램과 도구 서버가 곧 권한 경계가 됩니다.
네 번째 리스크는 속도입니다. 사람이 하루에 몇 번 실행하던 작업을 에이전트는 몇 초 안에 반복할 수 있습니다. 잘못된 명령 하나가 빠르게 대량 변경, 대량 요청, 대량 유출로 번질 수 있습니다. 보안팀은 “정확도”만 보지 말고 요청 속도 제한, 동시 실행 제한, 비용 한도, 비정상 반복 탐지를 같이 봐야 합니다.
이미지 출처: Anthropic Frontier Red Team LLM ATT&CK Navigator 공식 Figure 5.
관전 포인트
첫째, MITRE ATT&CK가 AI-native 행동을 어떻게 흡수하는지 봐야 합니다. Anthropic은 Verizon과 DBIR에 일부 결과를 반영했고, MITRE와도 논의 중이라고 밝혔습니다. 향후 ATT&CK에 자율 orchestration이나 AI-directed pivot 같은 항목이 들어가면 보안 제품의 탐지 룰도 바뀔 수 있습니다.
둘째, 에이전트 보안 표준 경쟁입니다. OWASP Agentic Applications Top 10은 에이전트 특유의 위험을 정리했고, CISA 계열 권고는 실제 배포의 조심스러운 조건을 제시합니다. 기업 보안팀은 둘 중 하나만 고르기보다, OWASP는 위험 분류표로, CISA는 배포 승인 기준으로 쓰는 방식이 현실적입니다.
셋째, Claude Code Security 같은 방어용 에이전트의 확산입니다. Anthropic은 Claude Code Security가 코드베이스를 스캔하고 패치를 제안하되, 최종 적용은 사람이 승인한다고 설명했습니다. 이 구조가 중요합니다. 공격자가 AI로 속도를 높인다면 방어자도 AI를 써야 하지만, 방어용 AI는 더 강한 승인과 감사 하네스 안에 있어야 합니다.
넷째, 기업 내부의 “에이전트 인벤토리”입니다. 지금 많은 조직은 어떤 팀이 어떤 AI 에이전트를 어떤 권한으로 쓰는지 모릅니다. 2026년의 보안 점검은 SaaS 계정 목록만으로는 부족합니다. 에이전트 계정, 연결 도구, 토큰, MCP 서버, 자동 실행 스케줄, 로그 보존 위치까지 목록화해야 합니다.
결론은 단순합니다. Anthropic의 AI 사이버 위협 지도는 “AI가 해킹을 한다”는 공포 뉴스가 아닙니다. 에이전트가 공격과 방어 양쪽에서 같은 구조를 쓰기 시작했다는 운영 신호입니다. 이제 보안의 핵심 질문은 모델이 얼마나 똑똑한가가 아니라, 그 모델이 어떤 권한으로, 어떤 도구를, 누구의 승인 아래, 어떤 로그를 남기며 실행되는가입니다.
출처와 더 읽을 거리
- Anthropic News – What we learned mapping a year’s worth of AI-enabled cyber threats: 2026년 6월 3일 공식 발표로, 832개 계정 분석과 MITRE ATT&CK 매핑 결과의 핵심 요약을 확인할 수 있다.
- Anthropic Frontier Red Team – Mapping AI-enabled cyber threats: Insights from the LLM ATT&CK Navigator: 13,873개 관측치, 482개 기법, ARiES 위험 점수, 공식 Figure를 포함한 장문 원문이다.
- Anthropic News – Disrupting the first reported AI-orchestrated cyber espionage campaign: 2025년 11월 공개된 Claude Code 악용 캠페인 분석으로, AI가 공격 단계 대부분을 수행한 사례의 근거 자료다.
- Anthropic News – Making frontier cybersecurity capabilities available to defenders: Claude Code Security 연구 프리뷰와 방어용 AI 워크플로를 설명하는 공식 발표다.
- MITRE ATT&CK: 공격자의 전술과 기법을 공통 언어로 정리하는 보안 지식베이스로, Anthropic 분석의 매핑 기준이다.
- OWASP Top 10 for Agentic Applications 2026: 에이전트형 AI 애플리케이션의 주요 위험을 분류한 공식 OWASP 자료로, 체크리스트 설계 기준으로 쓸 수 있다.
- CISA – Careful Adoption of Agentic AI Services: 에이전트형 AI를 업무에 도입할 때 필요한 신중한 배포, 격리, 복원성 원칙을 다룬 정부 권고 자료다.