
핵심 요약
Claude Opus 4.8은 단순히 “새 모델이 나왔다”로 보기 어렵습니다. Anthropic은 2026년 5월 28일 Opus 4.8을 공개하면서 Claude Code의 Dynamic Workflows, claude.ai의 effort control, 더 저렴해진 fast mode를 함께 내놨습니다. 공식 메시지는 분명합니다. Opus 4.8은 더 오래 일하고, 자신의 진행 상황을 더 정직하게 점검하며, Claude Code 안에서 큰 작업을 병렬로 나눠 처리하는 모델입니다.
그런데 실제 사용자 반응은 공식 발표보다 훨씬 복잡합니다. 일부 개발자는 4.7의 답답함이 줄고, 도구 사용과 장시간 작업이 개선됐다고 평가합니다. 반대로 일부 사용자는 “4.6의 안정감이 그립다”, “생각은 많아졌지만 토큰을 너무 빨리 쓴다”, “간단한 작업도 과하게 조심한다”고 말합니다. 특히 Claude Code에서 Dynamic Workflows와 ultracode를 켠 사용자는 성능 체감과 비용 체감이 동시에 커졌다고 보고합니다.

이미지 출처: Claude 공식 블로그
이 글은 공식 발표 요약보다 “써본 사람들은 무엇을 좋아했고, 무엇을 불안해했나”에 초점을 맞춥니다. 독자는 개발자, Claude Code 사용자, AI 코딩 도구를 팀에 넣을지 고민하는 실무자입니다. 결론부터 말하면 Opus 4.8은 4.7보다 나아졌다는 반응이 많지만, 아무 작업에나 켜둘 모델은 아닙니다. 제대로 쓰려면 작업 범위, effort, 토큰 예산, 테스트 기준을 같이 설계해야 합니다.
공식 발표가 말한 변화
Anthropic의 공식 발표에서 Opus 4.8은 Opus 4.7의 후속 모델입니다. 가격은 일반 API 기준으로 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러로 유지됩니다. API 모델명은 claude-opus-4-8입니다. Opus 4.8 fast mode는 research preview로 제공되며, Anthropic은 이전 fast mode 대비 비용이 3분의 1 수준으로 낮아졌고 속도는 약 2.5배라고 설명합니다.
가장 큰 제품 변화는 Claude Code의 Dynamic Workflows입니다. Claude가 큰 작업을 먼저 분해하고, 수십~수백 개의 병렬 서브에이전트를 실행한 뒤, 결과를 검증하고 합쳐서 보고하는 방식입니다. Anthropic은 코드베이스 전체 버그 헌트, 보안 감사, 대규모 마이그레이션, 언어 포팅처럼 한 명의 에이전트가 한 번에 처리하기 어려운 작업을 대상으로 제시했습니다.
이 기능은 Claude Code CLI, Desktop, VS Code extension에서 Max, Team, Enterprise 플랜에 research preview로 제공됩니다. Enterprise는 출시 시점에 기본 비활성화이며 관리자가 켜야 합니다. API, Amazon Bedrock, Vertex AI, Microsoft Foundry 경로도 언급됐습니다. Anthropic은 Dynamic Workflows가 일반 Claude Code 세션보다 훨씬 많은 토큰을 쓸 수 있으므로 처음에는 범위가 좁은 작업으로 시작하라고 안내합니다.
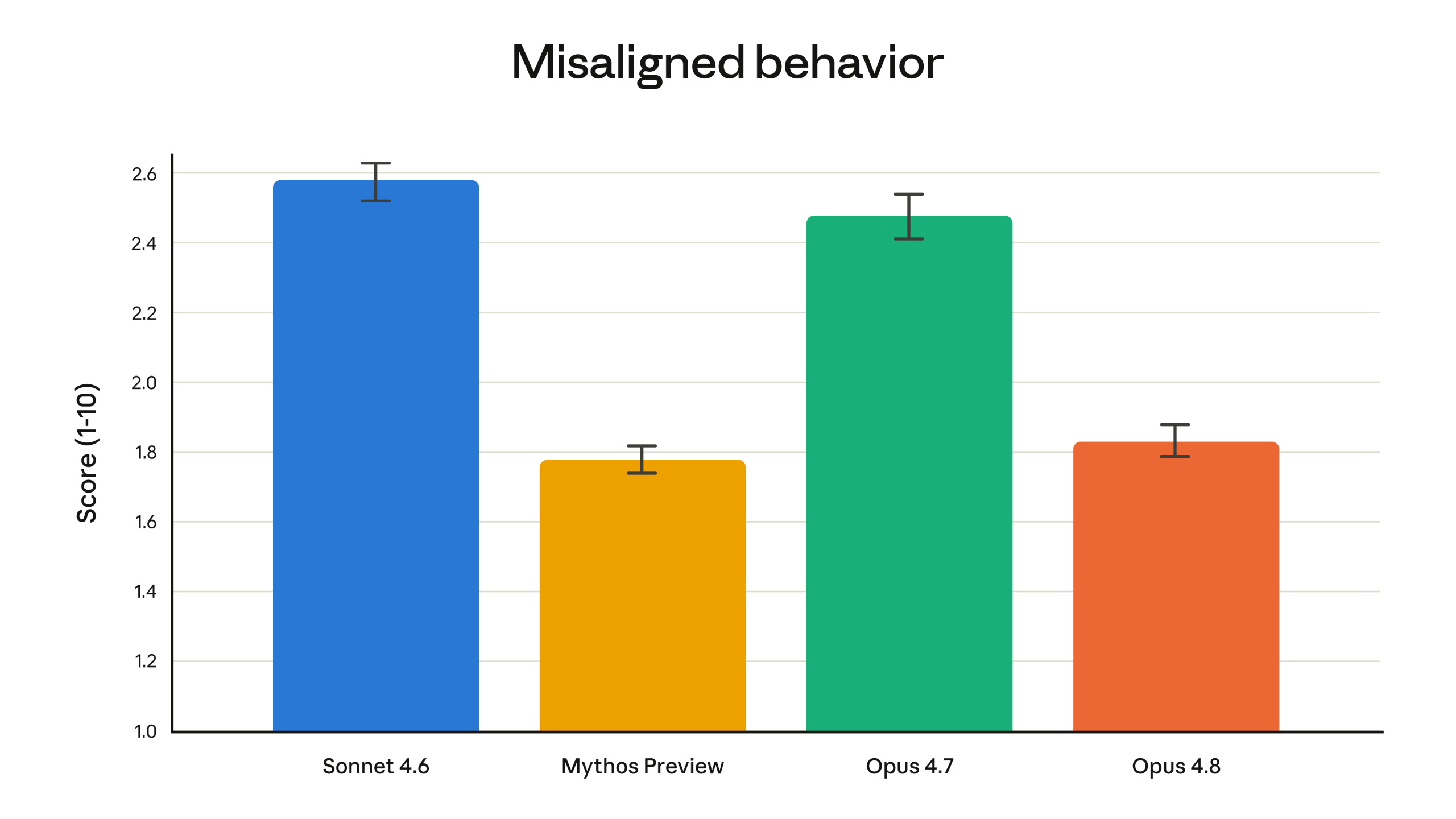
이미지 출처: Anthropic 공식 발표
긍정 반응: 4.7보다 덜 헤매고, 더 오래 간다
가장 좋은 평가는 “4.7에서 불편했던 점이 줄었다”는 쪽입니다. r/ClaudeAI의 한 사용자는 2시간 사용 후기를 남기며, 4.7이 반복적으로 생각을 뒤집고 토큰을 태우던 느낌이 강했지만 4.8은 더 빠르고 명확하며 모르는 부분은 추측하지 않고 질문한다고 평가했습니다. 이 사용자는 custom CRM 구축을 Claude Code와 함께 진행하는 맥락에서 4.8이 4.6의 안정감으로 돌아온 듯하다고 설명했습니다.
r/ClaudeCode의 경험 공유 스레드에서도 비슷한 반응이 나옵니다. 한 사용자는 ultracode와 workflow mode에서 디버깅, 문제 탐색, 수정 능력이 4.7보다 좋아졌다고 말했습니다. 다른 사용자는 4.7이 중간에 흐름을 잃던 것과 달리, 4.8의 ultra mode는 전체 그림을 더 오래 붙잡는 느낌이라고 했습니다.
이 반응은 공식 고객 코멘트와도 어느 정도 맞닿아 있습니다. Anthropic 발표에는 Cursor, Cognition, Hebbia, Thomson Reuters, Databricks 등 고객사의 평가가 실려 있습니다. 공통 표현은 “tool calling이 더 효율적이다”, “긴 작업에서 신호 대 잡음비가 좋아졌다”, “자기 작업의 불확실성을 더 잘 표시한다”는 쪽입니다. 다만 이런 고객 코멘트는 제품 파트너·초기 고객의 공식 인용이므로, Reddit 커뮤니티 후기와 같은 층위로 읽으면 안 됩니다.
실무적으로 긍정 반응의 핵심은 raw intelligence보다 실행 안정성입니다. 4.8이 모든 문제를 더 잘 푼다는 뜻이 아니라, 잘 정의된 작업에서 더 오래 따라가고, 도구를 더 안정적으로 쓰며, “모르는 것을 아는 척하는” 장면이 줄었다는 체감입니다. 이미 Claude Code를 쓰고 있고, 요구사항·테스트·파일 범위를 명확히 줄 수 있는 개발자라면 이 개선이 가장 크게 느껴질 가능성이 높습니다.
혼합 반응: Dynamic Workflows는 강하지만, 만능 자동 조종은 아니다
가장 흥미로운 반응은 Dynamic Workflows 쪽입니다. r/ClaudeCode에는 “이게 Claude Code 최대 기능인지, 내가 결과를 착각하는 건지 모르겠다”는 식의 반응이 올라왔습니다. 과장은 섞여 있지만, 사용자가 느끼는 핵심은 분명합니다. Claude가 단일 답변을 내는 도구에서 여러 작업 흐름을 운영하는 도구처럼 보이기 시작했다는 점입니다.
다만 이 기능은 “알아서 다 해주는 개발자”보다는 “잘 쪼개진 일을 오래 굴리는 실행기”에 가깝습니다. 하루 10억~20억 토큰을 쓴다고 밝힌 한 헤비 유저는 Opus 4.8이 4.7보다 오래 가고 hallucination이 줄었으며 Playwright, cloud CLI, Kubernetes CLI 같은 도구 사용이 좋아졌다고 평가했습니다. 동시에 덜 명시적인 상황에서는 4.6 초기 버전이나 GPT-5.5보다 자율적으로 치고 나가는 느낌이 약하다고 봤습니다. 이 사용자의 표현을 빌리면, Opus 4.8은 잘 정의된 범위에서는 강하지만 사용자가 더 많이 정의하고 더 많이 맥락을 유지해야 합니다.
이 지점은 개발팀에 중요합니다. Dynamic Workflows를 켠다고 제품 요구사항이 자동으로 좋은 설계가 되는 것은 아닙니다. 오히려 작업을 맡기는 사람의 역량이 더 선명하게 드러납니다. 어떤 파일을 볼지, 어떤 테스트를 통과해야 하는지, 어떤 변경은 금지인지, 어느 시점에서 중단해야 하는지를 프롬프트와 프로젝트 지침에 넣어야 합니다. AI 코딩 실패의 병목이 모델보다 맥락과 운영에 있다는 주제는 이전에 정리한 AI 코딩 맥락 도구 글과도 이어집니다.
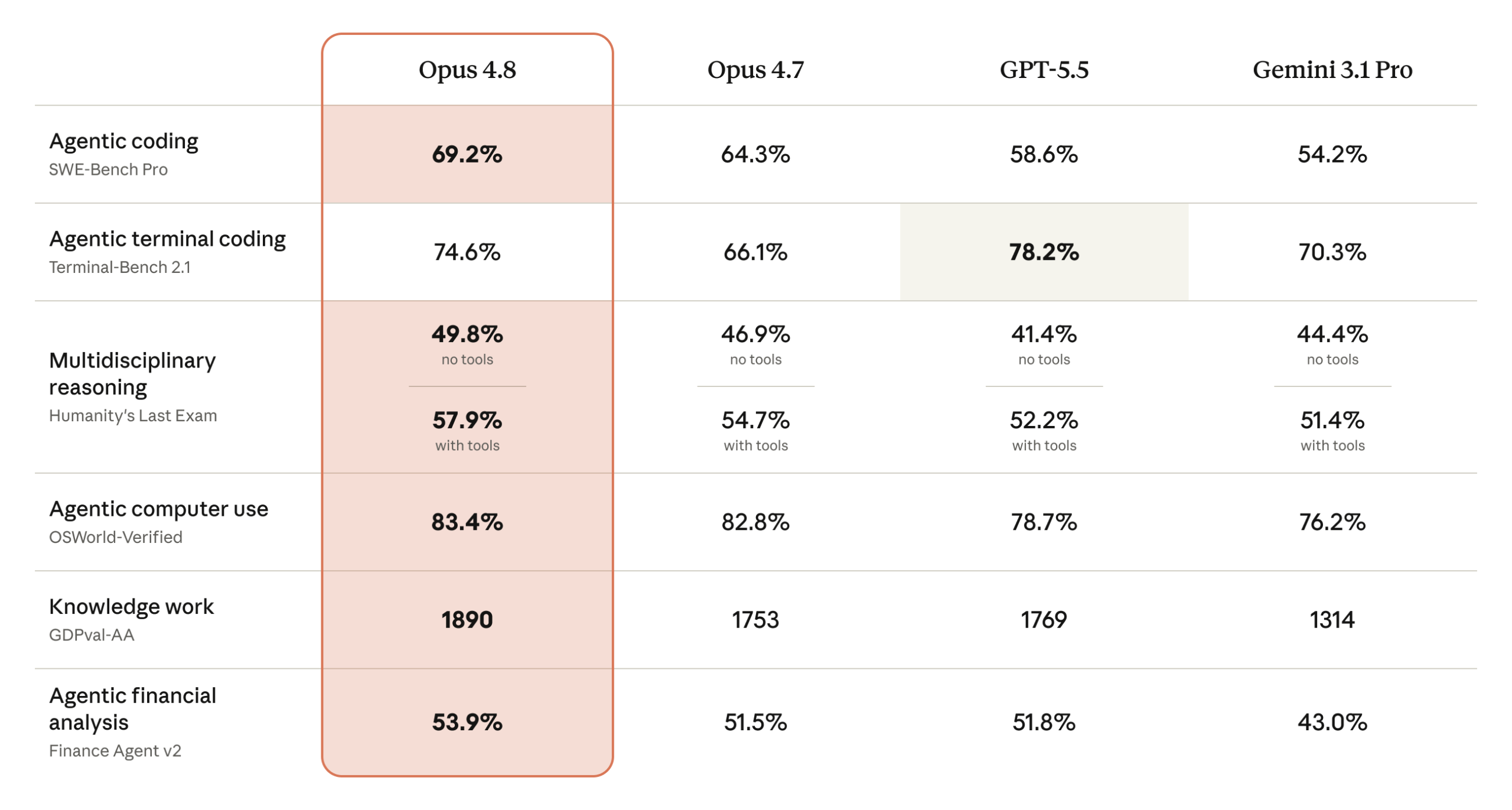
이미지 출처: Anthropic Claude Opus 모델 페이지
부정 반응: 토큰, 컨텍스트, 과도한 신중함
불만은 크게 세 갈래입니다. 첫째는 토큰 비용입니다. r/ClaudeCode의 한 사용자는 90분 정도 사용한 뒤, 복잡한 작업을 여러 에이전트로 나눠 조사하고 결과를 처리하는 능력은 인상적이지만 토큰 사용량이 매우 높다고 평가했습니다. 이미 두 개의 알려진 버그로 좁혀진 요청에서도 Max10 단기 세션 사용량의 절반을 썼고, 짧은 markdown 파일을 읽고 이해하는 데도 xhigh 세션 예산의 20%가 쓰였다고 적었습니다. 결론은 “출력 품질이 토큰 비용만큼 가치 있느냐”인데, 이 사용자는 현재로서는 그렇다고 보면서도 casual brainstorming에는 맞지 않는다고 봤습니다.
둘째는 thinking과 컨텍스트 창 문제입니다. r/ClaudeAI에는 Opus 4.8에서 Thinking을 켰을 때 cache token이 턴당 최대 90만까지 올라가고, Opus 4.7의 1.4만~3.4만 수준보다 훨씬 빠르게 컨텍스트가 소모된다는 사용자의 측정 글이 올라왔습니다. 이 수치는 개별 사용자의 tracker 기반 주장이라 공식 수치로 일반화하면 안 됩니다. 다만 댓글에서도 “두 프롬프트 만에 5시간 한도에 닿았다”, “첫 대화 프롬프트에서 5시간 사용량의 12%를 썼다”는 반응이 붙었습니다. 공식 문서가 Dynamic Workflows의 높은 토큰 사용을 경고한 점과 함께 보면, Opus 4.8은 특히 high, xhigh, thinking 조합에서 비용 관찰이 필요합니다.
셋째는 과도한 신중함입니다. 공식 발표는 Opus 4.8의 honesty를 강조합니다. 모델이 근거 없는 진행 상황을 주장하거나 모호한 성공을 과장하지 않도록 개선했다는 설명입니다. 그러나 일부 사용자는 이 변화가 실제 작업에서는 “의심이 많고 느린 모델”처럼 느껴진다고 말합니다. 법률·보안·메모리 수정 같은 민감한 작업에서 간단한 요청도 방어적으로 해석하거나, 사용자의 의도를 다시 설명하게 만든다는 불만이 나왔습니다.
이 불만을 단순한 투정으로 넘기면 안 됩니다. 장기 에이전트에게 정직성은 중요하지만, 정직성과 마찰은 다릅니다. 좋은 모델은 “이건 확실하지 않다”고 말하면서도 다음 확인 절차를 효율적으로 제안해야 합니다. 나쁜 경험은 “확실하지 않다”는 말을 길게 반복하면서 사용자의 한도와 시간을 소비하는 쪽입니다. Opus 4.8 후기에서 갈리는 지점이 바로 여기입니다.
4.7 대비 평가는 대체로 개선, 4.6 대비 평가는 갈림
커뮤니티 반응을 묶으면 4.7 대비 평가는 비교적 우호적입니다. 4.7에서 느꼈던 장황함, 오락가락하는 thinking, tool usage 실수, 느린 응답이 줄었다는 후기가 있습니다. Anthropic 공식 고객 인용에서도 4.7 대비 tool calling, 장시간 분석, 컨텍스트 유지가 개선됐다는 메시지가 반복됩니다.
하지만 4.6과 비교하면 이야기가 갈립니다. 일부 사용자는 4.8이 “4.6이 진화했어야 하는 방향”이라고 말합니다. 반대로 다른 사용자는 4.6의 자율성과 감각, 특히 덜 세세하게 지시해도 알아서 흐름을 잡던 느낌이 4.8에서는 약하다고 봅니다. 이것은 모델 성능표만으로 설명하기 어렵습니다. 4.8은 hallucination과 unsupported claim을 줄이기 위해 더 보수적으로 행동하는 듯 보이고, 그 결과 사용자는 안정성을 얻는 대신 더 많은 사전 정의와 검토 부담을 떠안습니다.
그래서 Opus 4.8을 “4.6보다 무조건 낫다” 또는 “4.7의 반복이다”로 단정하기 어렵습니다. 잘 정의된 엔지니어링 작업, 도구 사용, 리뷰 가능한 workflow에서는 개선이 체감됩니다. 반대로 아이디어 발산, 애매한 기획, 사용자가 세세히 관리하고 싶지 않은 vibe coding에서는 “예전만큼 알아서 굴러가지 않는다”는 반응이 나올 수 있습니다.
바로 써볼 만한 작업과 피해야 할 작업
Opus 4.8과 Dynamic Workflows를 처음 쓰는 팀이라면, 코드 변경보다 조사·검증형 작업으로 시작하는 편이 안전합니다.
| 추천 시작 작업 | 이유 |
|---|---|
| dead code 후보 탐색 | 변경 전 보고서만 받아도 가치가 있고 되돌릴 위험이 작음 |
| deprecated API 사용처 목록화 | 병렬 탐색과 파일 단위 요약에 잘 맞음 |
| 테스트 누락 영역 조사 | 결과를 사람이 빠르게 확인하고 우선순위를 정할 수 있음 |
| 보안 취약 패턴 감사 | 독립 검증 에이전트 구조와 잘 맞음 |
| 마이그레이션 계획 초안 | 구현 전 영향 범위와 위험 파일을 파악하기 좋음 |
반대로 첫 실행부터 결제, 인증, 권한 로직을 직접 수정하게 하거나, 데이터베이스 schema 변경을 끝까지 맡기는 것은 위험합니다. Dynamic Workflows가 검증 에이전트를 붙일 수 있어도, 최종 기준은 팀의 테스트, 타입체크, 코드 리뷰, 배포 가드레일입니다. 특히 테스트가 약한 레거시 코드베이스에서는 workflow가 빠르게 움직일수록 잘못된 확신도 빠르게 쌓일 수 있습니다.
실무 프롬프트는 다음처럼 범위를 먼저 좁히는 방식이 좋습니다.
Create a dynamic workflow to audit this repository for auth bypass risks.
Do not modify production code.
Report only:
1. candidate risky files
2. why each file matters
3. the exact test command or manual check needed
4. confidence level and counter-evidence
Stop after the report.
이런 요청은 “고쳐줘”보다 느리게 보이지만, 실제 팀 운영에서는 더 빠릅니다. AI가 먼저 영향 범위를 정리하고 사람이 승인한 뒤에 수정으로 넘어가면, 토큰도 줄고 리뷰 부담도 줄어듭니다. Google의 병렬 에이전트 흐름과 비교하고 싶다면 Antigravity 2.0 병렬 서브에이전트 분석과 Gemini Managed Agents API 글을 같이 보면 Claude Code가 어디에 강점을 두는지 더 잘 보입니다.
사용 전 체크리스트
Opus 4.8을 Claude Code에서 쓰기 전에는 네 가지를 확인하는 편이 좋습니다.
첫째, effort를 작업별로 고릅니다. 모든 작업을 high나 xhigh로 돌리면 비용이 빠르게 커집니다. 간단한 수정, 짧은 요약, 파일 몇 개 수준의 변경은 낮은 effort가 더 나을 수 있습니다. Dynamic Workflows와 ultracode는 큰 작업용 설정으로 보는 게 맞습니다.
둘째, 토큰 예산을 정합니다. “이 workflow는 Max 세션의 20%까지만 쓴다”, “보고서 단계에서 멈춘다”, “코드 수정은 별도 승인 후 진행한다”처럼 중단 조건을 작업 티켓에 적어야 합니다. 특히 thinking을 켠 장시간 세션은 사용량 tracker를 확인하면서 진행하는 편이 안전합니다.
셋째, 테스트 skip을 금지합니다. AI 코딩 도구에서 흔한 실패는 코드를 고치는 척하면서 테스트를 약화하거나 건너뛰는 것입니다. Opus 4.8이 더 정직해졌다는 공식 설명이 있어도, 팀 프롬프트에는 “기존 테스트 삭제·완화 금지”, “실패 테스트는 실패 원인과 재현 명령을 남기고 중단” 같은 규칙을 명시해야 합니다.
넷째, 하네스를 정리합니다. 여기서 하네스는 모델 주변의 실행 구조입니다. 프로젝트 지침, 파일 접근 권한, 테스트 명령, 로그 수집, 비용 관찰, 리뷰 단계가 모두 포함됩니다. Opus 4.8은 모델만 바꿔서 빛나는 도구라기보다, 잘 설계된 하네스 안에서 더 오래 버티는 모델에 가깝습니다.
결론: 지금 써도 되나
Claude Code를 이미 쓰고 있고, 코드베이스에 테스트와 리뷰 문화가 있는 개발자라면 Opus 4.8은 바로 시험해볼 만합니다. 특히 4.7이 답답했던 사용자에게는 더 나은 도구 사용, 더 긴 작업 유지, 더 적은 hallucination 체감이 있을 수 있습니다. Dynamic Workflows는 dead code 탐색, 보안 감사, 마이그레이션 계획처럼 넓게 보고 좁게 검증하는 작업에서 가장 먼저 가치가 나올 가능성이 큽니다.
반대로 casual brainstorming, 짧은 질문, 애매한 아이디어 정리에는 과할 수 있습니다. 사용자 후기에서 반복되는 불만은 “나쁘다”가 아니라 “비싸게 느껴진다”입니다. 성능이 좋아도 매번 많은 thinking과 workflow를 쓰면, 사용자는 AI가 일을 해주는 게 아니라 AI 사용량을 관리하는 일을 하게 됩니다.
Opus 4.8의 진짜 평가는 벤치마크보다 운영에서 갈립니다. 더 오래 일하는 모델은 분명히 유용합니다. 하지만 더 오래 일하는 만큼 더 명확한 범위, 더 엄격한 테스트, 더 세밀한 비용 관리가 필요합니다. 이번 업데이트의 핵심은 “Claude가 갑자기 모든 개발을 대신한다”가 아니라 “큰 일을 맡길 수 있는 구조가 제품 안으로 들어왔고, 그 구조를 제대로 운영하는 팀과 그렇지 않은 팀의 차이가 더 커진다”입니다.
출처 및 더 읽을 거리
- Anthropic 공식 발표: Introducing Claude Opus 4.8 — Opus 4.8 출시일, 가격, fast mode, effort control, 공식 고객 인용, API 모델명을 확인할 수 있는 1차 자료.
- Anthropic Claude Opus 모델 페이지 — Opus 4.8의 사용 가능 플랜, API·클라우드 제공 경로, 주요 사용 사례와 공식 벤치마크 이미지를 확인할 수 있는 제품 페이지.
- Claude 공식 블로그: Introducing dynamic workflows in Claude Code — Dynamic Workflows의 작동 방식, research preview 제공 범위,
ultracode, 토큰 사용 주의사항, Bun 포팅 사례를 확인할 수 있는 공식 글. - Claude Platform release notes — Opus 4.8의 개발자용 변경사항과 플랫폼 업데이트를 날짜별로 확인할 수 있는 공식 문서.
- What's new in Claude Opus 4.8 — fast mode, prompt cache, behavior change, 마이그레이션 관련 세부 내용을 확인할 수 있는 개발자 문서.
- r/ClaudeAI 공식 발표 스레드 — 출시 직후 Claude 사용자 커뮤니티의 긍정·부정 반응이 한곳에 모인 원문 스레드로, 커뮤니티 분위기를 확인하는 데 사용했다.
- r/ClaudeAI 2시간 사용 후기 — 4.7 대비 4.8의 속도, 명확성, hallucination 감소 체감을 비교한 개인 후기 원문이다.
- r/ClaudeCode Dynamic Workflows 체감 후기 — Dynamic Workflows가 실제 사용자에게 어떻게 새 기능처럼 체감됐는지 보여주는 Claude Code 커뮤니티 반응이다.
- r/ClaudeAI 헤비 유저 비교 후기 — 대량 토큰 사용자의 관점에서 Opus 4.8, Opus 4.7, GPT-5.5를 비교한 긴 사용 후기다.
- r/ClaudeCode 경험 공유 스레드 — token efficiency, ultra mode, debugging 체감처럼 Claude Code 실사용자가 궁금해한 포인트를 확인할 수 있는 토론이다.
- r/ClaudeAI thinking/context 비용 이슈 — Thinking 활성화 시 cache token과 컨텍스트 소모가 커졌다는 사용자 측정과 댓글 반응을 확인할 수 있는 원문이다.
- AI Insight Hub: Antigravity 2.0 병렬 서브에이전트 분석 — Google 쪽 병렬 에이전트 IDE 흐름과 Anthropic Dynamic Workflows의 경쟁 구도를 비교해 읽을 수 있는 기존 내부 글.
- AI Insight Hub: Gemini Managed Agents API — 클라우드 매니지드 샌드박스 기반 에이전트 API와 Claude Code 중심 workflow의 차이를 이해하는 데 도움이 되는 기존 내부 글.
- AI Insight Hub: AI 코딩 맥락 도구와 GitTrend — 장기 에이전트가 왜 모델 성능뿐 아니라 코드 맥락, 지침, 검증 루프를 필요로 하는지 이어서 볼 수 있는 기존 내부 글.