핵심 요약
회의 녹음은 생각보다 AI에게 어려운 입력입니다. 사람은 “저 사람이 멀리 앉아 있고, 에어컨 소리가 섞였고, 옆 사람이 동시에 말했구나”라고 대충 보정해서 듣지만, 음성인식 모델은 그 보정을 항상 잘하지 못합니다. 그래서 녹음 파일을 넣으면 그럴듯한 회의록이 나오다가도, 중요한 숫자나 고유명사에서 갑자기 말을 지어내거나 문장을 통째로 빠뜨립니다.
2026년 5월 공개된 Mega-ASR은 이 문제를 정면으로 겨냥한 오픈소스 ASR 모델입니다. 논문 제목부터 “in-the-wild” 음성인식입니다. 깨끗한 낭독 음성보다 잡음, 원거리, 반향, 대역폭 제한, 클리핑, 전송 끊김 같은 실제 환경을 훈련 목표로 잡았습니다. 공식 프로젝트 페이지는 7개 기본 음향 조건과 54개 복합 시나리오, 대규모 시뮬레이션 데이터, Qwen3-ASR-1.7B 기반 적응 가중치, 오디오 품질 라우터를 핵심으로 설명합니다.
결론부터 말하면, Mega-ASR은 회의 녹음 AI를 바로 대체하는 완제품이라기보다 “나쁜 녹음에서 기존 ASR이 무너지는 지점”을 보완하는 실전형 엔진에 가깝습니다. Zoom이나 Google Meet의 깔끔한 회의록 기능을 이미 잘 쓰는 사람에게는 당장 체감이 작을 수 있습니다. 반대로 소회의실 멀리서 딴 녹음, 현장 인터뷰, 콜센터 8kHz 파일, 식당·차량·행사장처럼 잡음이 많은 음성 데이터를 다루는 팀이라면 테스트해볼 가치가 큽니다.
이미지 출처: Mega-ASR 공식 프로젝트 페이지.
왜 회의 녹음은 유독 어렵나
일반 사용자는 음성인식을 “소리를 글자로 바꾸는 일”로 생각하기 쉽습니다. 하지만 회의 녹음은 단순 받아쓰기가 아닙니다. 회의실에서는 마이크와 발화자 거리가 계속 달라지고, 노트북 팬 소리와 키보드 소리, 프로젝터 소음, 의자 끄는 소리가 섞입니다. 여러 명이 동시에 말하고, 한 문장 안에서 한국어와 영어 제품명이 오가고, 숫자와 약어가 빠르게 지나갑니다.
문제는 ASR 오류가 균등하게 생기지 않는다는 점입니다. “오늘 회의는 여기까지 하겠습니다” 같은 문장은 대충 맞아도 업무상 중요한 “7월 15일까지 베타 고객 30곳”, “JVC가 50엔 하락”, “계약서 4조 2항” 같은 부분에서 틀리면 회의록의 가치가 크게 떨어집니다. 실제 업무에서는 의미 없는 문장 100개보다 숫자 하나, 담당자 이름 하나, 제품명 하나가 더 중요합니다.
Mega-ASR 논문은 이 병목을 “acoustic robustness bottleneck”으로 부릅니다. 음향 조건이 심하게 나빠지면 모델이 음성과의 연결을 잃고, 생략이나 환각을 만들 수 있다는 문제의식입니다. 그래서 Mega-ASR은 단순히 더 큰 모델을 붙이는 대신, 나쁜 음향 조건을 체계적으로 만들어 학습하고, 낮은 WER 구간과 높은 WER 구간에서 다른 학습 신호를 주는 방식으로 접근합니다.
이 맥락은 Google Workspace의 음성 기능과도 이어집니다. 예를 들어 Google I/O 2026에서 발표된 Gmail Live와 Workspace 음성 기능은 사용자가 말로 업무 앱을 검색하고 조작하는 방향을 보여줬습니다. 그러나 업무 음성 AI가 실제로 넓어지려면, 화려한 대화 UI만큼이나 “나쁜 녹음에서도 원문을 얼마나 잃지 않는가”가 중요해집니다.
Mega-ASR이 다르게 푼 방식
Mega-ASR은 Qwen3-ASR-1.7B를 기반으로 합니다. Hugging Face 모델 카드에 따르면 공개 패키지는 Qwen3-ASR-1.7B 기반 파일, Mega-ASR 적응 가중치, 오디오 품질 라우터를 포함합니다. 라우터는 입력 오디오마다 robust 경로를 쓸지, 기본 인식 경로를 쓸지 판단합니다. 이유는 단순합니다. 어려운 녹음에 맞춰 모델을 세게 조정하면 깨끗한 음성 인식 능력이 약간 떨어질 수 있기 때문입니다. 그래서 모든 음성에 무조건 robust 모드를 거는 대신, 필요할 때만 Mega-ASR 경로를 타게 합니다.
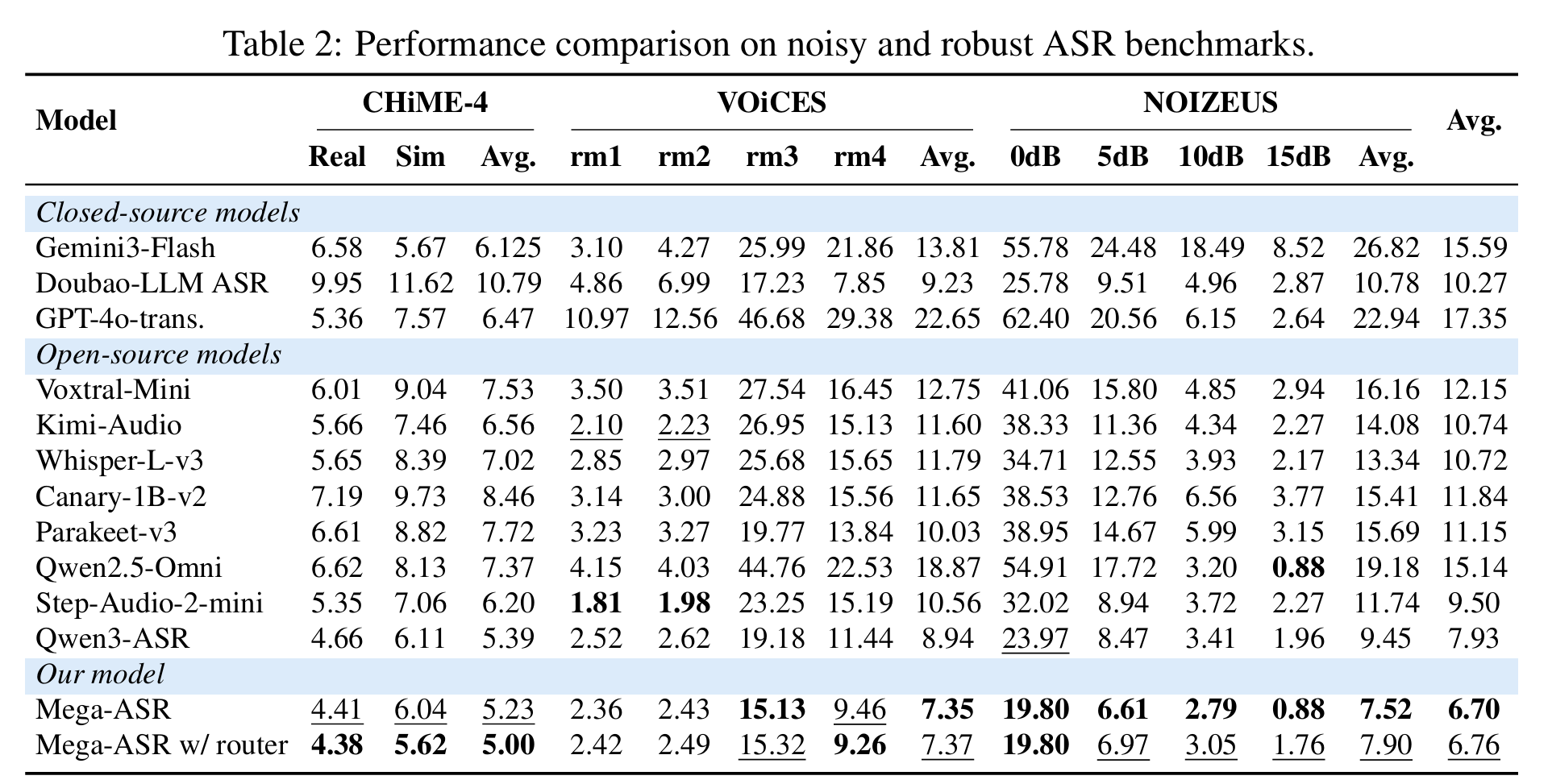
공식 논문과 프로젝트 페이지가 강조하는 데이터 쪽 핵심은 Voices-in-the-Wild-2M입니다. 여기에는 잡음, 원거리 음성, 장애물로 가려진 음성, 에코와 반향, 녹음 아티팩트, 전자적 왜곡, 전송 드롭아웃 같은 조건이 들어갑니다. 공식 페이지는 7개 기본 음향 효과와 54개 복합 환경을 설명하고, Hugging Face 데이터셋 카드는 공개 데이터셋 뷰 기준 645,925개 예시와 198GB 파일 크기를 표시합니다. 프로젝트 페이지에서는 더 큰 훈련 스케일 맥락에서 2.4M 또는 2.6M 샘플 표현이 함께 보이는데, 공개 데이터셋 카드와 논문·프로젝트 페이지의 표기가 완전히 같은 층위는 아니라는 점은 구분해서 읽어야 합니다.

이미지 출처: Mega-ASR 공식 프로젝트 페이지. 7개 기본 음향 조건과 54개 복합 시나리오로 난음성 데이터를 구성하는 방식을 보여주는 공식 자료다.
학습 방식도 실사용 문제에 맞춰져 있습니다. GitHub README는 Acoustic-to-Semantic Progressive SFT를 설명합니다. 먼저 WER 30% 미만, 50% 미만, 70% 미만처럼 점점 어려운 샘플로 encoder와 aligner를 훈련하고, 그다음 LLM 부분을 미세조정해 심하게 훼손된 음성에서도 문장 의미를 회복하도록 합니다. 이후 DG-WGPO라는 WER-gated policy learning을 적용해 낮은 오류 구간에서는 단어 단위의 정밀도를, 높은 오류 구간에서는 문장 단위 의미 회복을 더 강조합니다.
쉽게 말하면 Mega-ASR은 “잡음을 없앤 뒤 받아쓰기”만 하려는 모델이 아닙니다. 소리가 많이 망가졌을 때는 사람이 맥락으로 복원하듯, 문장 수준의 의미 회복까지 학습 목표에 넣습니다. 이 접근은 장점과 위험을 동시에 만듭니다. 심하게 훼손된 녹음에서 빈 출력이나 엉뚱한 반복을 줄일 수 있지만, 의미 복원은 언제나 과잉 추정 위험을 동반합니다. 회의록처럼 법적·재무적 책임이 있는 문서라면 원문 오디오와 타임스탬프 검수를 함께 둬야 합니다.
성능 수치는 어떻게 봐야 하나
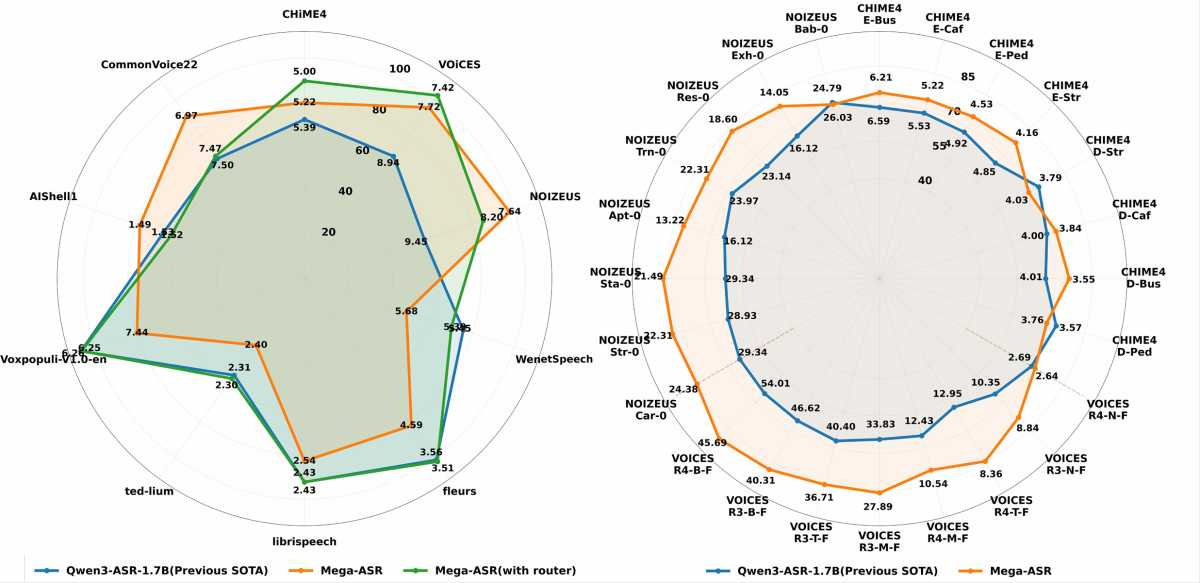
Mega-ASR 논문 초록은 두 가지 대표 수치를 제시합니다. VOiCES R4-B-F에서 45.69% 대 54.01%, NOIZEUS Sta-0에서 21.49% 대 29.34%로 기존 강한 시스템보다 낮은 WER를 기록했다는 내용입니다. 복합 음향 시나리오에서는 강한 오픈소스·폐쇄형 기준 모델 대비 30%가 넘는 상대 WER 감소도 보고합니다.
여기서 WER는 Word Error Rate, 즉 단어 오류율입니다. 낮을수록 좋습니다. 예를 들어 기준 문장 100단어 중 삽입, 삭제, 대체 오류가 총 30개면 WER 30%입니다. 한국어처럼 띄어쓰기와 형태소 처리가 애매한 언어에서는 CER, 즉 문자 오류율을 함께 보기도 합니다. Mega-ASR 평가 스크립트도 영어 계열에는 WER, 중국어 계열에는 CER를 쓰도록 안내합니다.
표로 보면 공식 수치의 의미가 더 분명합니다.
| 평가 항목 | 비교 수치 | 해석 |
|---|---|---|
| VOiCES R4-B-F | 45.69% vs 54.01% | 반향·원거리 등 어려운 조건에서 오류율을 낮춘 사례 |
| NOIZEUS Sta-0 | 21.49% vs 29.34% | 잡음이 섞인 음성에서 기존 강한 시스템보다 낮은 WER |
| 복합 in-the-wild 시나리오 | 30%+ 상대 WER 감소 | 단일 잡음보다 여러 악조건이 겹친 상황에서 강점 주장 |
다만 이 수치를 “내 한국어 회의록도 30% 좋아진다”로 읽으면 안 됩니다. 논문과 공개 모델 카드가 강조하는 주된 공개 예시는 영어와 중국어이며, Qwen3-ASR 자체는 한국어를 포함한 다국어를 지원하지만 Mega-ASR의 강건성 개선이 한국어 회의 녹음에서 같은 폭으로 나타난다고 단정할 공식 근거는 아직 부족합니다. 한국어 회의록 팀이라면 자체 샘플 50개 정도를 뽑아 Whisper, Qwen3-ASR, 상용 회의록 도구, Mega-ASR을 같은 기준으로 비교하는 편이 현실적입니다.
바로 테스트하려면
개발자가 가장 빠르게 확인하는 경로는 GitHub 코드와 Hugging Face 모델을 받는 방식입니다. 공식 README 기준 기본 흐름은 다음과 같습니다.
git clone https://github.com/xzf-thu/Mega-ASR.git
cd Mega-ASR
conda create -n mega-asr python=3.10 -y
conda activate mega-asr
pip install -r requirements.txt
python scripts/download.py
bash scripts/inference.sh --audio /path/to/meeting.wav
Hugging Face 모델 카드는 체크포인트를 ckpt/Mega-ASR 위치에 두고 infer.py로 실행하는 예시도 제공합니다.
python infer.py --audio /path/to/audio.wav --ckpt_dir ckpt/Mega-ASR
라우터를 끄고 robust 경로를 강제로 쓰는 테스트도 가능합니다.
python infer.py --audio /path/to/audio.wav --ckpt_dir ckpt/Mega-ASR --routing false
vLLM 경로도 있습니다. GitHub README는 qwen-asr[vllm] 설치 후 infer_vllm.py를 실행하는 방식을 안내합니다. 단, vLLM 엔트리포인트는 라우터 기반 동적 전환이 아니라 Mega-ASR LoRA를 materialized checkpoint로 만든 뒤 로드합니다. README는 8GB GPU에서 보수적인 기본값을 자동 적용한다고 설명하지만, 긴 회의 녹음과 배치 처리를 생각한다면 VRAM, 오디오 길이, 토큰 제한을 별도로 측정해야 합니다.
pip install -U "qwen-asr[vllm]"
python infer_vllm.py --audio /path/to/audio.wav
회의록 실전에 넣기 전 체크리스트
첫째, 테스트 오디오는 일부러 나쁜 샘플을 넣어야 합니다. 조용한 방에서 녹음한 5분짜리 파일만 넣으면 Mega-ASR의 장점을 보기 어렵습니다. 회의실 맨 뒤 노트북 마이크, 식당 인터뷰, 차량 통화, 행사장 질의응답, 8kHz 콜센터 파일처럼 실제로 문제를 일으키는 샘플을 모아야 합니다.
둘째, 평가는 전체 WER 하나로 끝내지 않는 편이 좋습니다. 회의록에서는 담당자 이름, 회사명, 제품명, 숫자, 날짜, 결정사항, 액션 아이템이 더 중요합니다. “전체 문장은 조금 틀렸지만 핵심 엔티티는 맞았는가”, “말이 겹친 구간을 빈칸으로 남겼는가, 아니면 그럴듯하게 지어냈는가”를 따로 봐야 합니다.
셋째, 화자 분리와 요약은 별도 문제로 봐야 합니다. Mega-ASR은 ASR 엔진입니다. 회의록 제품처럼 발화자 라벨링, 안건별 요약, 할 일 추출, 캘린더 연동까지 제공하는 앱이 아닙니다. 실제 제품에 넣으려면 diarization, 문장 정리, 민감정보 마스킹, 요약 모델, 검수 UI가 별도로 필요합니다. Keep 음성 노트와 Workspace 음성 기능처럼 사용자가 보는 제품 경험은 ASR 이후 단계에서 결정되는 경우가 많습니다.
넷째, 개인정보와 녹음 동의를 먼저 정해야 합니다. 회의 녹음은 참석자 음성, 고객 정보, 내부 전략, 건강·금융·법률 정보가 섞일 수 있습니다. 오픈소스 모델을 로컬에서 돌리면 클라우드 전송 부담은 줄일 수 있지만, 데이터 보관과 접근 권한, 전사문 삭제 정책은 여전히 남습니다. 특히 한국 업무 환경에서는 회의 녹음 고지와 참석자 동의, 사내 보안 정책을 먼저 맞추는 편이 안전합니다.
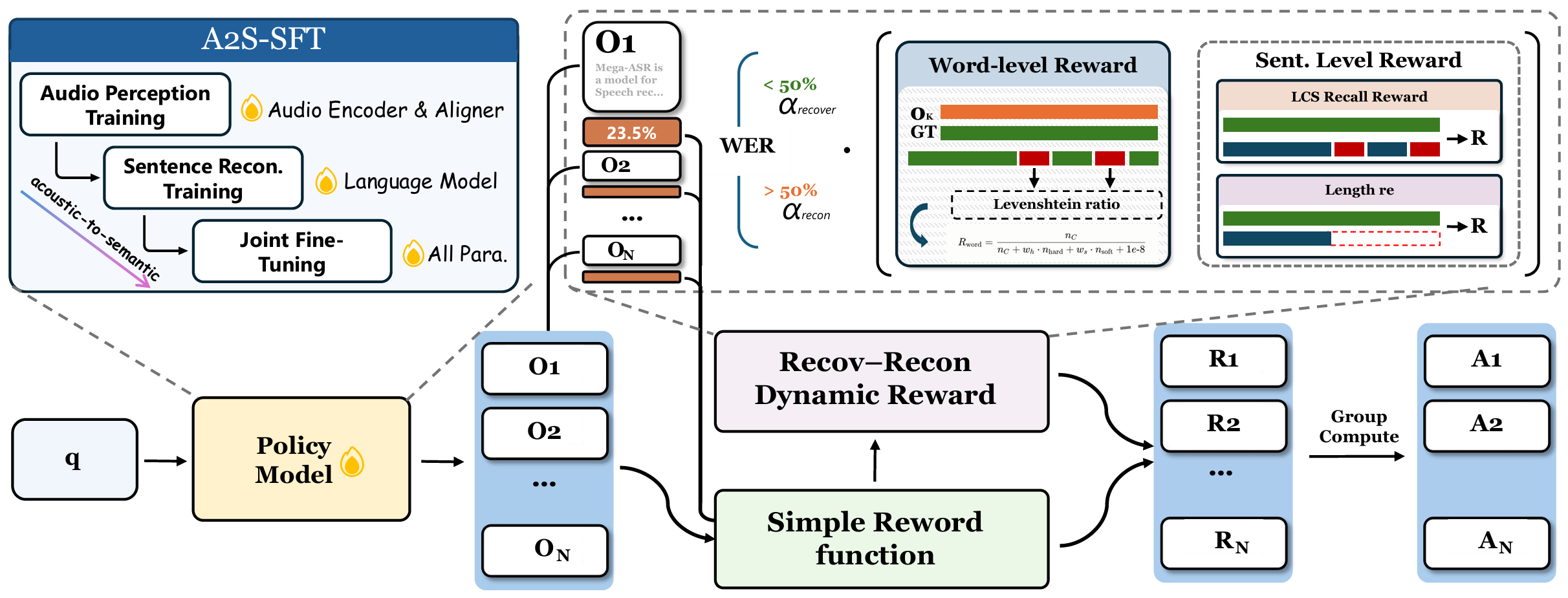
이미지 출처: Mega-ASR 공식 프로젝트 페이지. A2S-SFT와 DG-WGPO가 어떻게 난음성 회복 학습으로 이어지는지 설명하는 공식 파이프라인 이미지다.
누가 지금 써볼 만한가
가장 먼저 볼 팀은 음성 데이터가 이미 쌓여 있는데 기존 전사 품질 때문에 후처리 비용이 큰 곳입니다. 콜센터 QA, 리서치 인터뷰, 기자 녹취, 현장 점검, 교육·세미나 기록, 영업 미팅 분석이 여기에 들어갑니다. 이 팀들은 “완벽한 회의록 앱”보다 “기존보다 덜 빠뜨리는 ASR 엔진”만으로도 비용을 줄일 수 있습니다.
개발자와 데이터팀도 관심을 가질 만합니다. Apache-2.0 라이선스, Hugging Face 모델 공개, GitHub 코드 공개는 사내 실험 장벽을 낮춥니다. 다만 공개 README 기준 일부 RL 코드와 데이터 처리 파이프라인은 추후 공개 예정 항목으로 남아 있습니다. 연구 재현이나 자체 파인튜닝을 깊게 하려면 현재 공개 범위와 앞으로의 릴리스를 구분해야 합니다.
일반 사용자가 바로 앱처럼 쓰기에는 아직 거리가 있습니다. Gradio 데모나 간단한 웹 UI가 없는 것은 아니지만, 설치·GPU·체크포인트·오디오 포맷·평가 스크립트까지 다뤄야 합니다. 이미 Notta, Clova Note, Zoom, Google Meet, Teams 같은 회의록 제품을 쓰는 사람이라면 당장 바꿀 이유는 크지 않습니다. 다만 “왜 내 회의록 AI가 잡음 많은 파일에서 이상하게 지어내는가”를 이해하는 데 Mega-ASR은 좋은 사례입니다.
관전 포인트
첫 번째는 한국어 난음성 검증입니다. Qwen3-ASR은 한국어를 지원하지만, Mega-ASR의 공식 강건성 수치가 한국어 회의 녹음에서 어느 정도 재현되는지는 별도 벤치마크가 필요합니다. 한국어는 조사, 띄어쓰기, 외래어, 영어 약어 혼용 때문에 회의록 평가가 쉽지 않습니다.
두 번째는 라우터의 품질입니다. 깨끗한 음성에는 기본 경로를, 나쁜 음성에는 robust 경로를 쓰겠다는 아이디어는 실용적입니다. 하지만 실제 운영에서는 라우터가 틀릴 수 있습니다. 깨끗한 음성을 robust 경로로 보내면 오히려 기본 인식이 약해질 수 있고, 나쁜 음성을 기본 경로로 보내면 기존 실패가 반복됩니다.
세 번째는 상용 회의록 제품과의 결합입니다. Mega-ASR이 넓게 쓰이려면 모델 자체보다 파이프라인이 중요합니다. 업로드, 화자 분리, 문장 부호, 요약, 검색, 권한 관리, 삭제 정책까지 묶여야 사용자가 체감합니다. 음성 AI의 다음 경쟁은 “누가 더 말귀를 잘 알아듣나”와 동시에 “틀렸을 때 검수하기 쉬운가”가 될 가능성이 큽니다.
Mega-ASR의 의미는 “이제 회의록 문제가 끝났다”가 아닙니다. 오히려 반대입니다. 깨끗한 데모 음성에서 잘 되는 ASR과 실제 녹음에서 버티는 ASR은 다르다는 점을 공개 모델과 논문으로 다시 보여준 사건입니다. 회의록 AI를 업무에 넣으려는 팀이라면, 이제 모델 이름보다 녹음 품질, 실패 유형, 검수 흐름을 먼저 봐야 합니다.
출처와 더 읽을 거리
- Mega-ASR 공식 프로젝트 페이지: 공식 데모, 이미지 자료, 7개 음향 조건·54개 복합 시나리오, 결과 그래프를 한 번에 확인할 수 있는 1차 자료.
- Mega-ASR GitHub 저장소: 설치, 추론, vLLM 실행, 평가 스크립트, 라이선스와 공개 예정 항목을 확인할 수 있는 공식 코드 저장소.
- Mega-ASR arXiv 논문: VOiCES, NOIZEUS, in-the-wild benchmark 수치와 학습 방법을 확인할 수 있는 기술 보고서 원문.
- Hugging Face 모델 카드: zhifeixie/Mega-ASR: 모델 구성, Qwen3-ASR-1.7B 기반 여부, 라우터, Apache-2.0 라이선스, 빠른 실행 예시를 확인할 수 있는 다운로드 페이지.
- Hugging Face 데이터셋 카드: Voices-in-the-Wild-2M: 공개 데이터셋의 필드, 크기, 예시 수, 54개 하위 조건을 확인할 수 있는 공식 데이터셋 페이지.
- Qwen3-ASR GitHub 저장소: Mega-ASR의 기반 모델인 Qwen3-ASR의 언어 지원, vLLM·streaming·timestamp 관련 제약을 확인할 수 있는 공식 저장소.