EVA-Bench Data 2.0, 음성 에이전트 평가는 이제 말귀보다 업무 완료다
ServiceNow-AI가 EVA-Bench Data 2.0을 공개했다. 항공 고객지원, 기업 ITSM, 헬스케어 HRSD 3개 도메인, 121개 도구, 213개 시나리오로 음성 에이전트가 인증, 정책, 도구 호출, 최종 DB 상태까지 제대로 처리하는지...
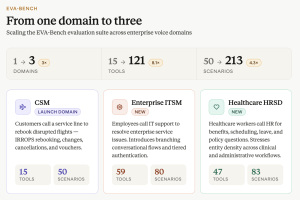
ServiceNow-AI가 EVA-Bench Data 2.0을 공개했다. 항공 고객지원, 기업 ITSM, 헬스케어 HRSD 3개 도메인, 121개 도구, 213개 시나리오로 음성 에이전트가 인증, 정책, 도구 호출, 최종 DB 상태까지 제대로 처리하는지...
Microsoft가 Build 2026에서 Agent Control Specification과 ASSERT를 공개했다. 에이전트 도입의 다음 과제는 더 똑똑한 모델이 아니라, 도구 실행 전 정책 검사, 평가 회귀, 승인 루프를 하네스 안에 넣는...
OpenAI가 제안한 제3자 평가 플레이북을 바탕으로 AI 벤치마크를 읽는 법을 정리했다. 하네스, 툴 설정, 예산, 오염, 보상 해킹을 확인해야 모델 점수가 실제 도입 판단으로 이어진다.
