핵심 요약
AI 코딩 도구를 써본 사람이라면 한 번쯤 이런 장면을 겪습니다. 모델은 똑똑한데, 우리 회사 코드베이스 앞에서는 갑자기 신입처럼 헤맵니다. 답변 문장은 그럴듯한데, 정작 파일을 찾고, 또 찾고, 관계없는 코드를 읽다가 마지막에는 틀린 수정안을 냅니다.
이 문제의 원인은 꼭 모델 성능만은 아닙니다. 더 큰 병목은 “AI가 지금 무엇을 읽어야 하는지”입니다. 회사 코드, 사내 문서, 회의록, 고객지원 FAQ가 정리되어 있지 않으면 아무리 최신 모델을 붙여도 AI는 먼저 주변을 뒤지는 데 시간을 씁니다.
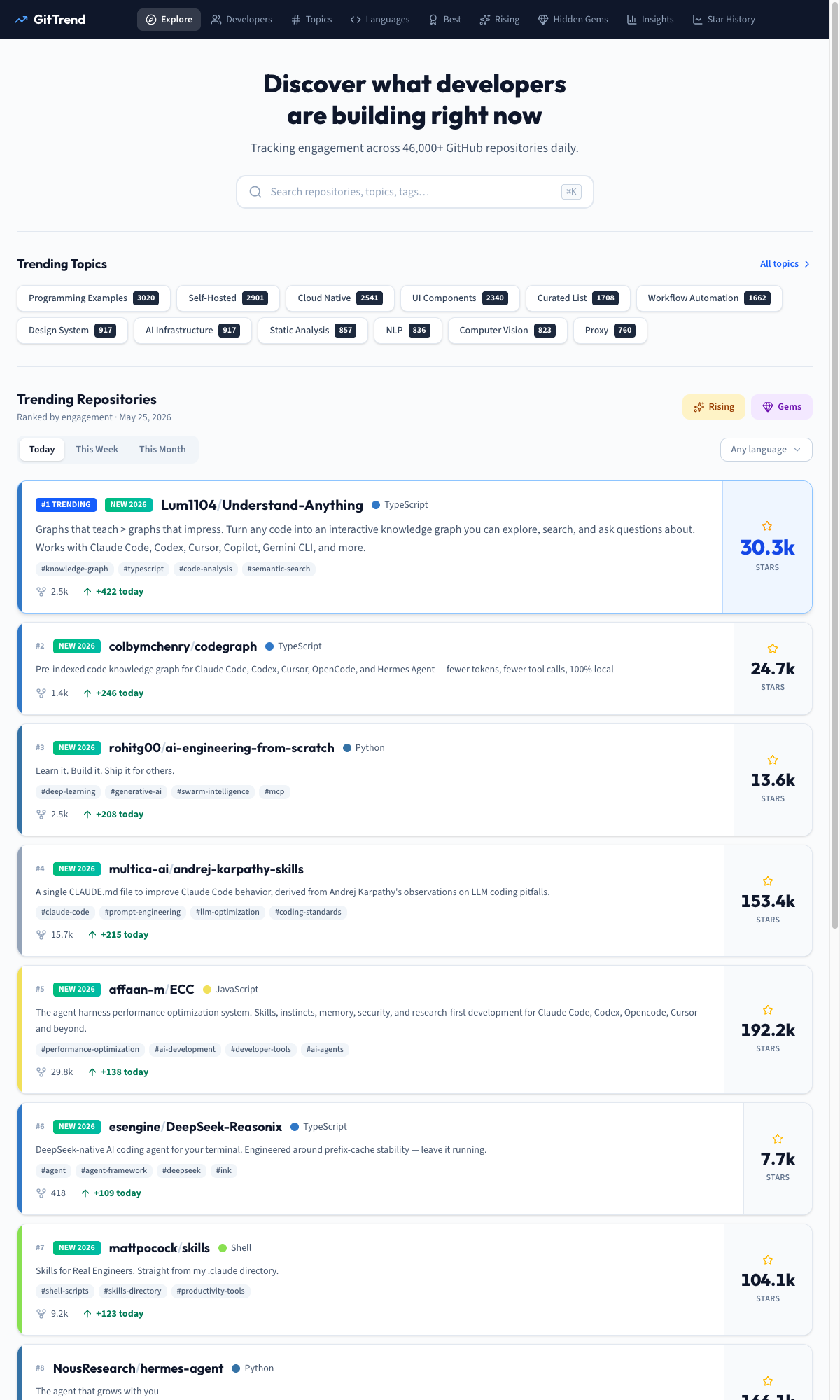
2026년 5월 25일 GitTrend 일일 랭킹은 이 흐름을 꽤 선명하게 보여줍니다. 확인 시점인 2026년 5월 26일 09:08 KST 기준, GitTrend의 상위권에는 Understand-Anything, codegraph, andrej-karpathy-skills, ECC, hermes-agent, superpowers처럼 코드 지식그래프, 에이전트 스킬, 메모리, 하네스 최적화 계열 도구가 여럿 올라와 있었습니다. 순위 숫자보다 중요한 건 공통 방향입니다. AI 코딩의 다음 경쟁은 “더 큰 모델”만이 아니라 “모델이 덜 헤매게 만드는 맥락 인프라”로 옮겨가고 있습니다.
이미지 출처: GitTrend 공식 페이지 화면 캡처, 2026-05-26 09:08 KST 확인.
GitTrend에서 무슨 일이 있었나
GitTrend는 GitHub 저장소의 engagement를 추적해 일일, 주간, 월간 흐름을 보여주는 사이트입니다. 사이트 설명에 따르면 46,000개 이상의 GitHub 저장소를 매일 추적하고, 데이터는 GitHub 기반 CC0 open data로 표시됩니다.
2026년 5월 25일 랭킹의 특징은 단순한 “AI 앱 만들기” 저장소가 아니라, AI 에이전트가 실제 업무를 덜 헤매게 만드는 도구가 앞줄에 모였다는 점입니다.
Understand-Anything은 코드베이스, 지식 베이스, 문서를 인터랙티브 지식그래프로 바꾸는 도구입니다. README는 Claude Code, Codex, Cursor, Copilot, Gemini CLI 등 여러 코딩 도구와 함께 쓸 수 있다고 설명합니다. 핵심은 “코드를 전부 읽는 것”이 아니라, 파일, 함수, 클래스, 의존 관계를 그래프와 검색 가능한 형태로 바꿔 AI와 사람이 함께 탐색하게 만드는 데 있습니다.
codegraph도 같은 문제를 다른 방식으로 겨냥합니다. README는 Claude Code, Codex, Cursor, OpenCode, Hermes Agent용 pre-indexed code knowledge graph라고 소개하고, “fewer tokens, fewer tool calls, 100% local”을 전면에 둡니다. 이 수치는 프로젝트 측 주장이라 독립 벤치마크로 받아들이면 안 되지만, 시장이 무엇을 원하고 있는지는 분명합니다. 더 많은 컨텍스트를 무작정 밀어 넣는 대신, 필요한 구조를 먼저 색인하고 작게 꺼내 쓰려는 요구입니다.
andrej-karpathy-skills는 코드 자체를 분석하는 도구라기보다, Claude Code가 덜 성급하게 일하도록 지침을 정리한 CLAUDE.md 계열 저장소입니다. ECC와 superpowers는 한 발 더 나아가 스킬, 메모리, 보안, 테스트 주도 개발, 서브에이전트 운영 같은 “작업 방식”을 패키지화합니다. 즉 상위권의 공통분모는 모델이 아니라 운영입니다.
이 흐름을 “개발자만의 이야기”로 보면 절반만 본 겁니다. 회사 자료를 AI에게 맡기려는 직장인에게도 같은 문제가 생깁니다. 매주 쌓이는 회의록, 영업 제안서, 고객 문의, 제품 정책 문서가 폴더 안에 흩어져 있으면 AI는 답을 만드는 시간이 아니라 자료를 찾는 시간부터 씁니다. 개발팀의 코드 지식그래프와 일반 회사의 문서 색인은 본질적으로 같은 문제를 풉니다. 구글이 Antigravity 2.0을 Agent-First IDE로 내세운 흐름도 결국 모델이 혼자 똑똑해지는 문제보다, IDE 안에서 어떤 맥락과 도구를 계속 연결할지의 문제로 볼 수 있습니다.
이미지 출처: GitTrend 공식 페이지 화면 캡처, 2026-05-26 09:08 KST 확인.
왜 모델보다 맥락이 병목이 되나
AI 코딩 에이전트는 사람처럼 “이미 알고 있는 프로젝트 감각”을 갖고 시작하지 않습니다. 새 세션이 열리면 현재 디렉터리, 지시 파일, 최근 대화, 사용자가 열어준 파일, 검색 결과를 바탕으로 임시 지도를 만듭니다. 이 지도가 부정확하면 모델이 아무리 강해도 틀린 곳을 고칩니다.
가장 흔한 실패는 세 가지입니다.
첫째, 관련 파일을 못 찾습니다. 예를 들어 결제 오류를 고치라고 했는데, 실제 로직은 payments/, 화면은 checkout/, 정책 문서는 docs/billing/에 흩어져 있을 수 있습니다. AI가 rg로 몇 번 찾다가 놓치면, 표면적으로 보이는 파일만 고칩니다.
둘째, 너무 많이 읽습니다. 큰 레포에서는 파일 몇십 개만 읽어도 대화 컨텍스트가 급격히 무거워집니다. OpenAI의 prompt caching 문서가 비용과 지연 시간을 줄이기 위해 반복되는 긴 입력을 어떻게 캐시할지 설명하는 이유도 여기에 있습니다. 긴 컨텍스트는 공짜가 아닙니다. 비용, 지연 시간, 주의 분산이 같이 따라옵니다.
셋째, 팀의 암묵지를 모릅니다. “우리 회사는 API 응답 에러 포맷을 이렇게 맞춘다”, “이 서비스는 레거시라 직접 수정하지 않는다”, “이 테스트는 배포 전 반드시 돌린다” 같은 정보는 모델의 일반 지식 안에 없습니다. 이런 정보가 AGENTS.md, CLAUDE.md, copilot-instructions.md, SKILL.md 같은 파일로 정리되어야 AI가 매번 같은 실수를 덜 합니다.
그래서 GitTrend 상위권의 도구들이 흥미롭습니다. 이들은 “더 똑똑한 모델”을 만들지 않습니다. 대신 모델이 읽어야 할 것을 줄이고, 이미 정리된 지도를 건네고, 팀의 일하는 방식을 반복 가능한 파일로 바꿉니다.
세 가지 도구군으로 나눠 보면 쉽다
이번 랭킹을 이해하는 가장 쉬운 방법은 도구를 세 부류로 나누는 것입니다.
첫 번째는 코드 지도 도구입니다. Understand-Anything과 codegraph가 여기에 가깝습니다. 코드베이스를 파일 목록이 아니라 구조화된 그래프로 바꿉니다. 함수가 어디서 호출되는지, 라우트가 어느 핸들러로 이어지는지, 어떤 변경이 어느 영역에 영향을 주는지를 빠르게 찾게 해줍니다. 사람에게는 온보딩 지도이고, AI에게는 “먼저 이 주변을 봐라”라는 탐색 가이드입니다.
두 번째는 지침과 스킬 도구입니다. OpenAI의 Codex 문서는 Codex가 작업 전에 AGENTS.md를 읽고, 전역 지침과 프로젝트별 지침을 레이어링한다고 설명합니다. Anthropic의 Claude Code 문서도 CLAUDE.md가 조직, 사용자, 프로젝트, 로컬 범위에 따라 로드될 수 있다고 설명합니다. Claude Code Skills 문서는 SKILL.md가 YAML frontmatter와 본문 지침으로 구성되고, description이 언제 스킬을 불러올지 판단하는 데 쓰인다고 밝힙니다. GitHub Copilot 문서 역시 .github/copilot-instructions.md와 AGENTS.md 같은 repository instructions를 설명합니다.
세 번째는 에이전트 운영 방식입니다. ECC나 superpowers 같은 저장소는 “코딩 에이전트가 어떤 절차로 일해야 하는가”를 다룹니다. 계획을 먼저 세울지, 테스트를 먼저 쓸지, 서브에이전트를 언제 나눌지, 보안 검사를 어디에 끼울지 같은 문제입니다. 개발자가 보기에는 방법론이고, 회사 입장에서는 책임 소재와 품질 관리의 문제입니다.
이 세 부류가 합쳐지면 AI 코딩 도구의 역할이 바뀝니다. 예전에는 “이 함수 고쳐줘”라고 말하면 AI가 파일을 뒤지며 답을 만들었습니다. 이제는 “이 프로젝트의 지도, 규칙, 작업 절차는 이미 레포 안에 있다. 그 안에서 고쳐라”에 가까워집니다.
회사 업무로 옮기면 무슨 뜻인가
개발팀이 아니어도 이 변화는 곧 체감됩니다. 사내 AI 도입이 실패하는 대표적인 이유도 비슷하기 때문입니다.
예를 들어 고객지원팀이 “지난달 환불 정책 관련 문의를 요약해줘”라고 AI에게 묻는다고 합시다. 문의 로그는 Zendesk에 있고, 환불 정책은 Notion에 있고, 예외 처리 기준은 슬랙 고정 메시지에 있고, 실제 승인 권한은 스프레드시트에 있을 수 있습니다. AI가 이 자료를 한 번에 정확히 찾지 못하면 답은 부정확해집니다.
영업팀도 마찬가지입니다. “A 고객사에 보낼 제안서를 만들어줘”라고 했을 때 필요한 맥락은 제품 소개서만이 아닙니다. 과거 미팅 메모, 견적 이력, 경쟁사 언급, 법무팀이 금지한 표현, 최신 가격표가 같이 필요합니다. 이 자료가 검색 가능한 형태로 묶이지 않으면 AI는 예쁜 문장을 만들 뿐, 실제로 쓸 수 있는 제안서를 만들기 어렵습니다.
회의록도 좋은 예입니다. 매주 회의록을 AI가 요약해도, 결정 사항이 프로젝트 문서와 연결되지 않으면 다음 주에 같은 논의를 반복합니다. 반대로 회의록, 이슈, 문서, 코드 변경이 연결되어 있으면 AI는 “지난주 결정이 이 PR에 반영됐는가” 같은 질문에 답할 수 있습니다.
결국 “AI에게 맡긴다”는 말은 챗봇 창을 하나 여는 뜻이 아닙니다. 회사가 가진 자료를 작은 지도, 명확한 규칙, 접근 권한, 최신성 표시로 바꾸는 일입니다. 개발자 도구 시장에서 코드 지식그래프와 스킬이 뜨는 이유는 일반 사무 자동화에도 그대로 적용됩니다.
지금 당장 해볼 수 있는 최소 세팅
무작정 GitTrend 상위 도구를 설치할 필요는 없습니다. 먼저 작은 레포나 작은 문서 묶음에서 시작하는 편이 안전합니다.
첫 단계는 프로젝트 지침 파일을 만드는 것입니다. Codex를 쓰는 팀이라면 AGENTS.md, Claude Code를 쓰는 팀이라면 CLAUDE.md, Copilot을 많이 쓰는 팀이라면 .github/copilot-instructions.md부터 시작할 수 있습니다.
cat > AGENTS.md <<'EOF'
# Project context
This repository contains the customer support admin dashboard.
## Before editing
- Read README.md and docs/architecture.md first.
- Do not change billing logic without checking docs/billing-policy.md.
- Use pnpm test for changed TypeScript files.
- Keep API error responses in the format documented in docs/api-errors.md.
## Done criteria
- Relevant tests pass.
- No unrelated refactor is included.
- Any user-visible behavior change is documented in docs/changelog.md.
EOF
두 번째 단계는 작은 색인 실험입니다. Understand-Anything이나 codegraph 같은 도구를 바로 핵심 사내 레포에 넣기보다, 공개 예제 레포나 내부 샘플 레포 하나로 테스트해 보세요. 설치 스크립트를 그대로 실행하기 전에는 README, 설치 스크립트, 권한 범위, 생성 파일 위치를 확인해야 합니다. 특히 회사 코드에서는 “100% local”이라는 문구만 보고 판단하지 말고, 실제로 외부 API 호출이 없는지, 어떤 파일이 저장되는지 확인해야 합니다.
세 번째 단계는 문서를 줄이는 것입니다. 이상하게 들릴 수 있지만, AI에게 모든 문서를 한 번에 주는 것은 좋은 전략이 아닙니다. 팀 표준, 보안 규칙, 테스트 명령처럼 항상 필요한 정보만 상위 지침에 두고, 세부 정책은 링크나 하위 문서로 나누는 편이 낫습니다. Claude Code Skills 문서가 description으로 필요한 스킬을 고르게 하는 구조를 둔 것도 같은 이유입니다. 매번 전체 매뉴얼을 읽히는 대신, 필요한 때 필요한 조각만 부르는 방식입니다.
주의할 점: 랭킹은 품질 보증서가 아니다
GitTrend 랭킹은 “지금 개발자들이 무엇에 반응하는가”를 보여주는 신호입니다. 하지만 랭킹이 곧 안정성, 보안성, 장기 유지보수를 보장하지는 않습니다.
특히 이번 상위권 저장소 중 일부는 별표 수와 engagement가 매우 빠르게 움직이고 있습니다. 이런 저장소는 문서가 빠르게 바뀌고, 설치 방식이 달라지고, 아직 검증되지 않은 주장이 README에 남아 있을 수 있습니다. “토큰 57% 감소”, “툴 호출 71% 감소”, “비용 35% 절감” 같은 표현은 흥미로운 제품 메시지이지만, 우리 회사 코드베이스에서도 같은 결과가 난다는 뜻은 아닙니다.
보안도 중요합니다. AI 코딩 도구는 단순 라이브러리보다 권한이 큽니다. 레포를 읽고, 파일을 만들고, 셸 명령을 실행하고, 때로는 외부 네트워크에 접근합니다. curl | bash 형태의 설치 명령은 편하지만, 회사 환경에서는 그대로 복사해 실행하기 전에 내용을 봐야 합니다. API 키, 고객 데이터, 비공개 설계 문서가 색인 파일에 섞이지 않도록 제외 규칙도 필요합니다. 실제로 GitHub 내부 repo 유출 사건의 VS Code 확장 보안 경고는 IDE 확장, 로컬 자격증명, AI 코딩 설정이 한곳에 모일 때 위험 범위가 얼마나 커질 수 있는지 보여줍니다.
또 하나의 함정은 “지침 과다”입니다. 팀이 AI 실수를 줄이겠다고 AGENTS.md나 CLAUDE.md에 모든 규칙을 밀어 넣으면, 오히려 중요한 지시가 묻힙니다. GitHub Copilot 문서가 custom instruction을 짧고 자기완결적인 문장으로 쓰라고 권하는 이유도 여기에 있습니다. AI에게 필요한 것은 백과사전이 아니라, 지금 작업에서 지켜야 할 우선순위입니다.
관전 포인트
첫째, AGENTS.md, CLAUDE.md, SKILL.md 같은 파일형 지침이 사실상의 표준으로 굳어질 가능성이 큽니다. OpenAI, Anthropic, GitHub Copilot이 각자 다른 이름과 로딩 규칙을 쓰지만, “레포 안에 AI 작업 규칙을 둔다”는 방향은 이미 겹칩니다.
둘째, 로컬 색인과 지식그래프 경쟁이 커질 것입니다. 큰 컨텍스트 창이 계속 늘어나도, 모든 파일을 매번 읽히는 방식은 비용과 정확도 면에서 비효율적입니다. 앞으로 좋은 AI 코딩 환경은 모델 성능보다 “어떤 정보를 언제 꺼내 주는가”로 갈릴 수 있습니다.
셋째, 개발팀의 실험이 일반 업무 자동화로 번질 것입니다. 코드 지식그래프가 사내 문서 그래프로, 스킬 파일이 업무 매뉴얼로, 에이전트 하네스가 부서별 운영 절차로 확장되는 그림입니다. 지금은 개발자들이 먼저 겪고 있지만, 1년 뒤에는 법무, 영업, 고객지원, 재무팀도 같은 질문을 하게 될 가능성이 높습니다. “우리 자료를 AI가 이해하려면 먼저 어떻게 정리해야 하나?”
결론은 단순합니다. 내 AI가 코딩을 못하는 이유가 항상 모델의 머리 때문은 아닙니다. 답은 만들어도 맥락을 모르면 실제 코드를 고치지 못합니다. 모델 앞에 놓인 책상이 엉망이면, 좋은 모델도 한참을 뒤져야 합니다. GitTrend 상위권을 차지한 에이전트 툴링들은 그 책상을 정리하는 도구들입니다. 다음 AI 도입의 승부처는 더 화려한 프롬프트가 아니라, 회사와 코드베이스의 맥락을 얼마나 깔끔하게 색인하고 관리하느냐가 될 것입니다.
출처와 더 읽을거리
- GitTrend – Discover Trending GitHub Repositories: 2026년 5월 25일 기준 에이전트 맥락 도구들이 GitHub 트렌드 상위권에 올라온 흐름을 확인한 원자료다.
- Lum1104/Understand-Anything: 코드베이스를 지식그래프와 시각화로 분석하는 도구의 기능 범위와 설치 방식을 확인할 수 있는 저장소다.
- colbymchenry/codegraph: 코드 구조를 그래프로 색인해 AI 코딩 도구에 전달하는 접근을 보여주는 프로젝트 원문이다.
- multica-ai/andrej-karpathy-skills: Karpathy식 스킬 파일을 에이전트 작업 지침으로 구성한 사례를 확인할 수 있는 저장소다.
- affaan-m/ECC: AI 코딩 에이전트를 위한 컨텍스트 관리와 실행 보조 도구의 실제 구현을 볼 수 있는 프로젝트다.
- obra/superpowers: 에이전트 작업 방식을 스킬과 절차로 패키징하는 흐름을 보여주는 오픈소스 사례다.
- OpenAI Docs – Prompt caching: 긴 컨텍스트를 반복 사용할 때 비용과 지연 시간을 줄이는 공식 캐싱 동작을 확인할 수 있는 문서다.
- OpenAI Developers – Custom instructions with AGENTS.md: Codex가 레포 안의 AGENTS.md를 어떻게 읽고 작업 규칙으로 쓰는지 설명하는 공식 가이드다.
- Claude Code Docs – How Claude remembers your project: Claude Code의 프로젝트 메모리와 지침 파일 로딩 방식을 확인할 수 있는 공식 문서다.
- Claude Code Docs – Extend Claude with skills: Claude Code에서 스킬을 정의하고 재사용하는 구조를 설명하는 공식 자료다.
- GitHub Docs – About customizing GitHub Copilot responses: Copilot 응답을 레포 지침으로 조정하는 방식과 작성 원칙을 확인할 수 있는 GitHub 공식 문서다.