
핵심 요약
Claude Opus 4.8을 둘러싼 비용 논란은 “Anthropic이 가격을 올렸나?”라는 질문으로 시작하면 답이 잘 안 보입니다. 공식 가격은 오히려 단순합니다. Anthropic은 2026년 5월 28일 Opus 4.8을 공개하면서 일반 API 가격을 Opus 4.7과 같은 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러로 유지한다고 밝혔습니다. fast mode는 Opus 4.8에서 입력 10달러, 출력 50달러로 책정됐고, 기존 Opus 4.6·4.7 fast mode보다 낮아졌습니다.
그런데 사용자 체감은 다릅니다. 특히 Claude Code와 Thinking을 같이 쓰는 개발자들은 “가격표는 그대로인데 세션 한도가 너무 빨리 줄어든다”고 말합니다. Reddit r/ClaudeAI에는 Opus 4.8에서 Thinking을 켠 뒤 캐시 토큰이 턴마다 크게 불어난다는 측정 글이 올라왔고, 댓글에는 5시간 한도가 두세 번의 프롬프트 안에 닿았다는 반응도 붙었습니다. 이 수치는 개인 측정이므로 공식 수치처럼 일반화하면 안 됩니다. 하지만 논란이 생긴 이유는 분명합니다. 이제 사용자가 체감하는 비용은 단순한 모델 단가가 아니라 effort, thinking, 도구 호출, 컨텍스트 캐시, Claude Code 사용량 한도의 조합으로 결정됩니다.

이미지 출처: Anthropic 공식 발표
이 글은 이미 발행한 Claude Opus 4.8 후기와 Dynamic Workflows 분석의 후속 보강입니다. 이전 글이 “더 오래 일하는 모델과 사용자 반응”을 다뤘다면, 이번 글은 더 좁게 들어갑니다. 왜 Thinking을 켠 Opus 4.8이 비싸게 느껴지는지, 사용자는 무엇을 설정해야 하는지, 팀은 어떤 하네스를 만들어야 하는지 정리합니다.
가격표는 바뀌지 않았다
먼저 확인할 사실부터 정리해야 합니다. Anthropic의 Opus 4.8 공식 발표는 일반 사용 가격이 Opus 4.7과 같다고 적고 있습니다. API 모델명은 claude-opus-4-8이고, 일반 가격은 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러입니다. Claude Opus 제품 페이지도 같은 가격을 안내하면서 prompt caching을 쓰면 최대 90%, batch processing을 쓰면 50%까지 비용을 줄일 수 있다고 설명합니다.
가격 문서에서 흥미로운 부분은 fast mode입니다. fast mode는 research preview이며 Opus 4.8에서는 입력 100만 토큰당 10달러, 출력 100만 토큰당 50달러입니다. 같은 문서에서 Opus 4.6·4.7 fast mode는 입력 30달러, 출력 150달러로 표시됩니다. 즉 fast mode만 놓고 보면 Opus 4.8은 이전 fast mode보다 싸졌습니다.
그런데 이 숫자만으로 “비용 논란은 착각”이라고 말하면 절반만 보는 겁니다. 사용자가 Claude Code에서 보는 것은 API 청구서만이 아닙니다. Pro, Max, Team 같은 구독형 상품에서는 5시간 단위 사용량, 모델별 한도, 컨텍스트 크기, 도구 호출량이 합쳐진 체감 한도가 중요합니다. 같은 1달러 단가라도 한 요청이 더 많은 reasoning과 tool call을 만들면 한도는 더 빨리 줄어듭니다.
논란의 중심은 effort다
Opus 4.8의 핵심 변화 중 하나는 effort입니다. Anthropic 문서에 따르면 Opus 4.8의 기본 effort는 Claude API와 Claude Code를 포함한 모든 surface에서 high입니다. effort는 모델이 응답에 얼마나 많은 토큰을 쓰려 하는지 조절하는 신호입니다. 낮추면 더 빠르고 저렴해질 수 있지만 품질이 일부 떨어질 수 있고, 높이면 더 깊게 reasoning하지만 토큰 사용이 늘 수 있습니다.
공식 effort 문서는 다섯 단계를 설명합니다.
| effort | 공식 용도 요약 | 비용 관점에서의 해석 |
|---|---|---|
low |
짧고 범위가 좁은 작업 | 속도와 비용 우선 |
medium |
비용을 아끼면서 무난한 품질이 필요한 작업 | 기본값 후보로 시험할 만함 |
high |
복잡한 reasoning, 어려운 코딩, agentic task | Opus 4.8 기본값 |
xhigh |
장시간 agentic·coding 작업 | 토큰 예산이 큰 작업용 |
max |
토큰 제약 없는 최고 능력 지향 | 상시 기본값으로 쓰면 위험 |
Claude Code 문서는 여기에 ultracode를 추가로 설명합니다. ultracode는 API effort level이 아니라 Claude Code 설정입니다. 모델에는 xhigh를 보내고, 실질적인 작업에는 Dynamic Workflows를 붙여 substantive task를 병렬 에이전트 흐름으로 계획하게 합니다. 그래서 사용자는 “effort 하나 올렸을 뿐”이라고 느낄 수 있지만, 실제로는 도구 호출과 서브에이전트 실행 구조까지 바뀔 수 있습니다.
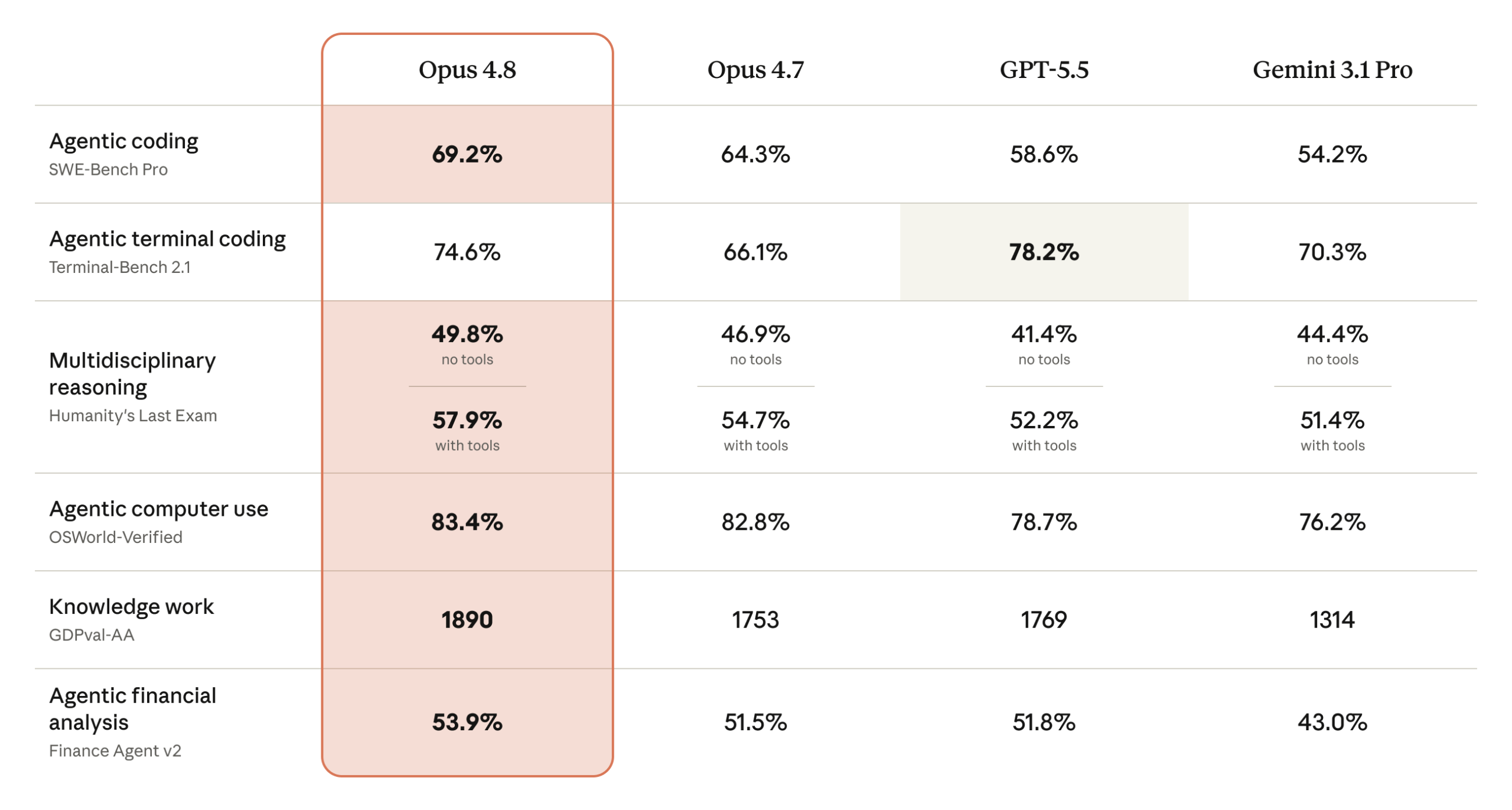
이미지 출처: Anthropic Claude Opus 모델 페이지
Thinking은 공짜가 아니다
비용 논란에서 가장 헷갈리는 단어는 Thinking입니다. 사용자는 화면에서 접힌 회색 reasoning 요약만 보거나, 아예 redacted된 thinking block을 볼 수 있습니다. 하지만 Claude Code 문서는 접혀 있거나 redacted되어도 생성된 Thinking 토큰에는 과금된다고 설명합니다. 즉 “눈에 안 보이는 reasoning”도 비용 회계에서는 사라지지 않습니다.
Opus 4.8 문서는 adaptive thinking을 사용한다고 설명합니다. API에서는 thinking: {type: "adaptive"}를 명시해야 Thinking이 켜지고, 수동 budget_tokens 방식은 Opus 4.7 이후 지원되지 않습니다. 기존처럼 “이번 요청은 thinking budget 32,000토큰까지만”이라고 고정 예산을 주는 방식이 아니라, effort와 task 성격에 따라 모델이 얼마나 생각할지 정하는 방식으로 이동한 겁니다.
여기서 체감 비용 문제가 생깁니다. 공식 문서의 이상적인 설명은 간단합니다. adaptive thinking은 간단한 턴에서는 덜 생각하고, 복잡한 multi-step 문제에서는 더 생각합니다. 하지만 실제 Claude Code 세션은 간단한 채팅이 아닙니다. 긴 시스템 프롬프트, 프로젝트 지침, 파일 읽기, 도구 결과, 이전 thinking 요약, 캐시 prefix가 계속 쌓입니다. 사용자는 “한 문장 물었는데 왜 이렇게 한도가 줄지?”라고 느끼지만, 모델 입장에서는 이미 큰 작업장의 맥락을 들고 있는 상태일 수 있습니다.
Reddit의 이번 논란은 이 지점에서 터졌습니다. 한 사용자는 자체 token usage tracker 기준으로 Opus 4.8에서 Thinking을 켰을 때 턴당 cache token이 최대 90만까지 올라갔다고 주장했습니다. 또 Thinking을 끄면 약 1.2만 cache token 수준으로 돌아간다고 적었습니다. 이 주장은 개인 환경과 측정 도구에 의존하므로 공식 사실로 받아들이면 안 됩니다. 다만 댓글 반응까지 보면, 일부 사용자가 “짧은 시간 안에 5시간 한도가 사라진다”고 느끼는 현상은 실제 불만으로 존재합니다.
공식 설명과 커뮤니티 주장은 구분해야 한다
여기서 중요한 건 양쪽을 섞지 않는 겁니다. Anthropic 공식 문서는 Opus 4.8이 Opus 4.7보다 같은 effort level에서 불필요한 Thinking 토큰을 줄이고, tool triggering과 compaction recovery를 개선했다고 설명합니다. 또 Opus 4.8은 high effort를 기본값으로 쓰지만, 사용자가 명시적으로 effort를 낮추거나 올릴 수 있다고 안내합니다.
반면 커뮤니티 주장은 “특정 환경에서 Thinking을 켜면 캐시와 컨텍스트가 눈덩이처럼 불어난다”는 경험 보고입니다. 이것이 버그인지, 설정 조합 문제인지, Claude Code의 표시 방식 문제인지, 특정 tracker의 계산 방식 문제인지는 아직 단정하기 어렵습니다. 글을 쓰는 시점인 2026년 6월 1일 기준, Anthropic 공식 발표나 문서에서 “Opus 4.8 Thinking이 항상 턴당 90만 cache token을 생성한다”는 설명은 확인되지 않습니다.
그래서 실무 결론은 둘 중 하나를 믿으라는 게 아닙니다. 공식 문서가 말하는 제어 장치가 있으니 그걸 써야 하고, 커뮤니티 측정값은 위험 신호로 보고 자신의 작업에서 재측정해야 합니다. 특히 팀 단위 도입이라면 “다른 사람이 Reddit에 올린 숫자”보다 “우리 저장소에서 대표 작업 20개를 돌렸을 때 토큰 분포가 어떻게 나오는가”가 훨씬 중요합니다.
개발자가 바로 바꿔야 할 설정
Claude Code에서 Opus 4.8을 쓰는 개발자는 먼저 effort를 눈으로 확인해야 합니다. Claude Code 문서 기준으로 /effort 메뉴, /model의 effort slider, --effort flag, CLAUDE_CODE_EFFORT_LEVEL, settings 파일로 설정할 수 있습니다. low, medium, high, xhigh는 세션을 넘어 유지될 수 있고, max와 ultracode는 기본적으로 세션용입니다.
일상적인 코드 수정이나 파일 몇 개짜리 리팩터링이라면 high가 항상 최선은 아닐 수 있습니다. 비용 민감도가 높다면 medium에서 시작하고, 실패한 작업만 high나 xhigh로 올리는 방식이 낫습니다. 반대로 대규모 마이그레이션, 오래 걸리는 디버깅, 여러 도구 호출이 필요한 탐색 작업은 xhigh가 맞을 수 있습니다. 중요한 것은 “처음부터 가장 높은 값을 켜두지 않는 것”입니다.
API를 쓰는 팀이라면 effort를 코드에 명시하는 편이 좋습니다. 기본값에 기대면 모델 업데이트나 surface별 정책 변경 때 비용이 흔들릴 수 있습니다.
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
output_config={"effort": "medium"},
thinking={"type": "adaptive"},
messages=[
{
"role": "user",
"content": "이 변경의 위험 파일을 먼저 찾아줘. 코드는 수정하지 말고 보고서만 작성해줘.",
}
],
)
print(response.content[0].text)
에이전트 루프를 직접 운영한다면 task budget도 검토할 만합니다. Anthropic의 task budgets 문서는 task_budget이 agentic loop 전체를 위한 목표 예산이고, max_tokens는 개별 요청의 hard cap이라고 설명합니다. 또 xhigh나 max effort에서는 요청마다 생각하고 행동할 공간을 주기 위해 max_tokens를 최소 64k에서 시작하라고 안내합니다. 다만 task budgets는 Claude Code나 Cowork surface에서는 지원되지 않고, Messages API에서 beta header를 붙여 쓰는 기능입니다.
“비싸다”는 불만의 진짜 의미
이번 논란의 핵심은 Opus 4.8이 나쁘다는 뜻이 아닙니다. 오히려 반대에 가깝습니다. Opus 4.8은 더 오래 생각하고, 도구를 더 적극적으로 쓰고, 장시간 작업을 더 잘 붙잡으려 합니다. 문제는 그 능력이 비용 회계에서 사라지지 않는다는 점입니다. 모델이 더 많은 일을 하면 토큰도 더 많이 씁니다.
예전에는 사용자가 메시지 개수로 AI 사용량을 감각적으로 이해했습니다. “오늘 몇 번 물어볼 수 있나”가 중요했습니다. 하지만 agentic coding에서는 이 감각이 무너집니다. 한 번의 “이 버그 고쳐줘”가 파일 수십 개 읽기, 테스트 실행, 실패 로그 해석, 새 계획 작성, 재시도, 요약까지 포함할 수 있습니다. 겉으로는 한 프롬프트지만 내부적으로는 작은 프로젝트입니다.
그래서 Opus 4.8의 비용 관리는 모델 선택보다 작업 설계 문제에 가깝습니다. 코드 수정을 바로 맡기기 전에 “조사만 해라”, “수정 금지”, “상위 5개 위험 파일만 보고하라”, “토큰 예산을 넘기면 중단하라” 같은 조건을 줘야 합니다. AI 코딩에서 실행 구조가 모델만큼 중요하다는 점은 이전에 정리한 하네스와 에이전트 용어 글과도 이어집니다. Opus 4.8은 잘 만든 하네스 안에서는 강력하지만, 무제한 자동 조종처럼 쓰면 비용부터 터집니다.
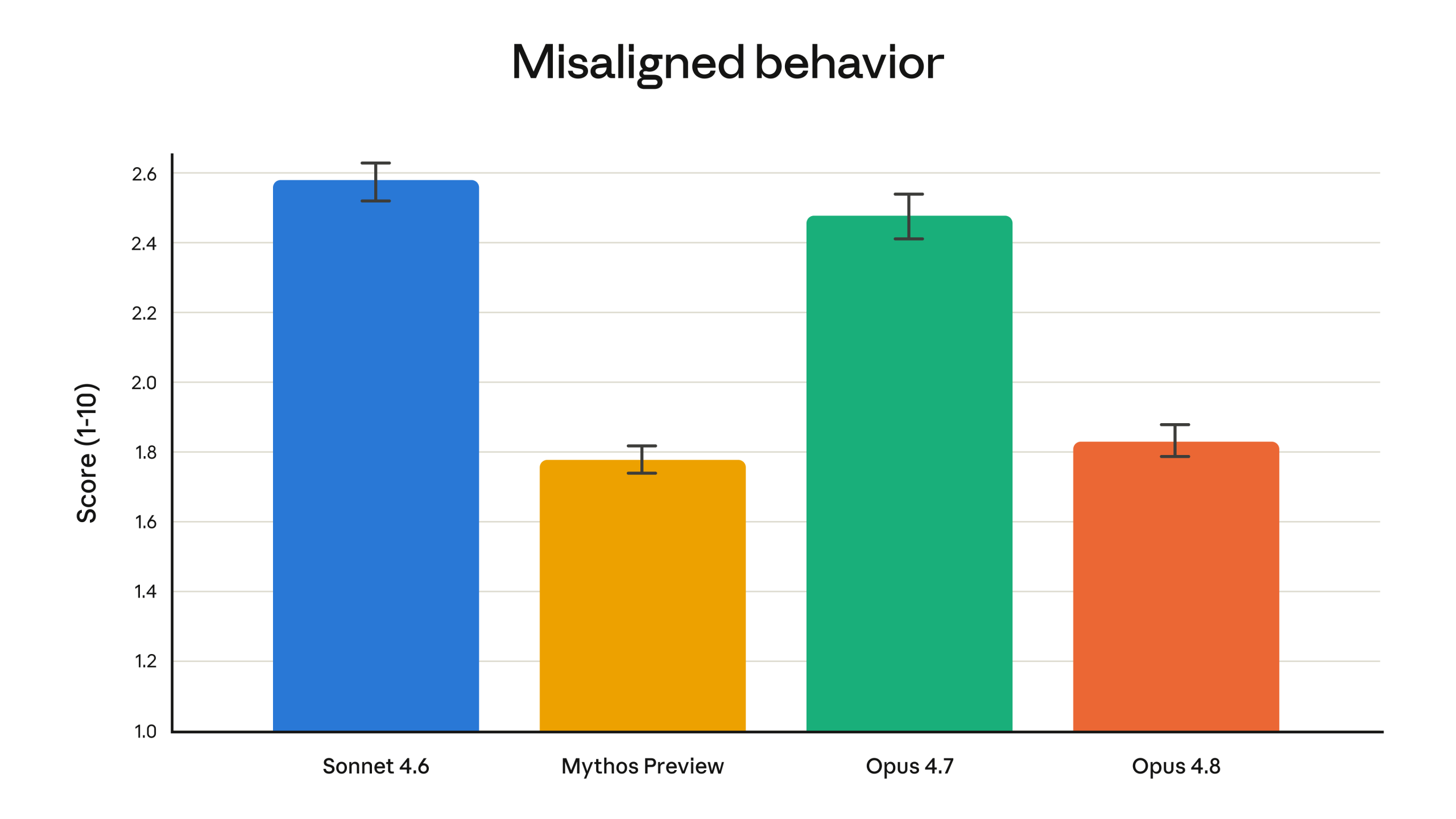
이미지 출처: Anthropic 공식 발표
추천 사용법
Opus 4.8을 지금 쓰는 개발자라면 이렇게 나누는 편이 현실적입니다.
| 작업 유형 | 추천 설정 | 이유 |
|---|---|---|
| 짧은 질문, 파일 1~3개 수정 | medium 또는 low |
high Thinking을 쓸 이유가 작음 |
| 일반 코딩 보조, 리뷰, 테스트 실패 분석 | high |
기본값으로 품질과 비용 균형이 좋음 |
| 장시간 디버깅, 복잡한 레거시 탐색 | xhigh |
도구 호출과 깊은 reasoning이 필요 |
| 대규모 마이그레이션, Dynamic Workflows | ultracode 또는 별도 계획 단계 |
처음부터 수정하지 말고 조사와 실행을 분리 |
| 민감한 운영 코드, 결제·권한·인증 | 보고서 모드 후 사람 승인 | 비용보다 검증과 책임 소재가 중요 |
Claude Code에서 특히 피해야 할 패턴은 “긴 세션을 계속 이어가며 모든 일을 같은 effort로 처리하는 것”입니다. 컨텍스트가 커질수록 작은 요청도 큰 요청처럼 계산될 수 있습니다. 작업이 끝났으면 /clear나 새 세션으로 맥락을 줄이고, 큰 작업은 조사 세션과 수정 세션을 분리하는 편이 낫습니다. Thinking이 꼭 필요한 턴과 그렇지 않은 턴을 나누는 습관도 필요합니다.
기업 팀이라면 더 엄격해야 합니다. 모델 사용량 로그, 작업 종류별 평균 토큰, 실패한 작업의 재시도 횟수, 테스트 통과율을 같이 봐야 합니다. 단순히 “Opus 4.8이 비싸다”가 아니라 “우리 코드베이스에서 인증 변경은 평균 몇 토큰, 문서 생성은 몇 토큰, 마이그레이션 계획은 몇 토큰인가”를 측정해야 합니다. 그래야 Sonnet, Opus, 다른 모델을 라우팅할 기준도 생깁니다.
결론
Claude Opus 4.8의 비용 논란은 가격 인상 논란이 아닙니다. 공식 가격표는 Opus 4.7과 같고, fast mode는 이전 세대보다 낮아졌습니다. 논란의 본질은 Thinking과 effort가 사용자의 한도 체감을 바꾸고 있다는 점입니다. 특히 Claude Code처럼 도구 호출과 긴 컨텍스트가 자연스럽게 붙는 환경에서는 한 프롬프트가 실제로는 큰 agentic loop가 될 수 있습니다.
따라서 지금 필요한 질문은 “Opus 4.8을 써도 되나?”가 아니라 “어떤 작업에 어느 effort를 쓸 것인가?”입니다. 짧은 작업에는 낮은 effort, 일반 코딩에는 high, 장시간 에이전트 작업에는 xhigh나 ultracode를 쓰되, 조사와 수정 단계를 분리해야 합니다. API 팀은 effort와 task budget을 명시하고, Claude Code 사용자는 세션 길이와 Thinking 상태를 의식적으로 관리해야 합니다.
Opus 4.8은 더 똑똑한 모델이면서 동시에 더 엄격한 운영을 요구하는 모델입니다. 성능은 좋아졌지만, 성능을 켜는 스위치가 곧 비용 스위치이기도 합니다. 이 점을 이해하지 못하면 “가격은 그대로라는데 왜 한도가 사라지지?”라는 불만이 반복될 수밖에 없습니다.
출처 및 더 읽을 거리
- Anthropic 공식 발표: Introducing Claude Opus 4.8 — Opus 4.8 출시일, 일반 가격, fast mode, effort control, Dynamic Workflows, 공식 성능 주장과 이미지 출처를 확인한 1차 자료다.
- Anthropic Claude Opus 제품 페이지 — Opus 4.8의 사용 가능 플랜, API·클라우드 제공 경로, 1M 컨텍스트와 공식 벤치마크 이미지를 확인할 수 있는 제품 자료다.
- Claude API Docs: Pricing — Opus 4.8 일반 가격, fast mode 가격, long context pricing, tool use token count를 확인한 공식 가격 문서다.
- Claude API Docs: What’s new in Claude Opus 4.8 — Opus 4.8의 high effort 기본값, adaptive thinking, 1M context, 128k max output, 4.7 대비 동작 변화를 확인한 개발자 문서다.
- Claude API Docs: Effort —
low,medium,high,xhigh,max의 의미와 Opus 4.8에서 effort를 어떻게 비용·품질 조절 장치로 써야 하는지 확인한 공식 문서다. - Claude API Docs: Task budgets — agentic loop 전체의 토큰 예산을 어떻게 측정하고 조절할지,
task_budget과max_tokens의 차이를 확인한 공식 문서다. - Claude Code Docs: Model configuration — Claude Code에서
/effort,ultracode,CLAUDE_CODE_EFFORT_LEVEL, extended thinking, 1M context 설정이 어떻게 작동하는지 확인한 공식 문서다. - Reddit r/ClaudeAI: Opus 4.8 + Thinking is draining context windows 40–60x faster — Thinking 활성화 후 cache token과 5시간 한도 체감이 급격히 악화됐다는 사용자 측정과 댓글 반응을 확인한 커뮤니티 원문이다.
- AI Insight Hub: Claude Opus 4.8 후기 정리 — 이번 글의 선행 내부 글로, Opus 4.8과 Dynamic Workflows의 사용자 반응과 장시간 에이전트 관점을 이어서 볼 수 있다.
- AI Insight Hub: 하네스와 에이전트 용어 정리 — 모델 단독 성능보다 실행 하네스, 권한, 테스트, 비용 관찰이 왜 중요한지 이해하는 데 도움이 되는 내부 배경 글이다.