
핵심 요약
AI 안전 필터의 진짜 비용은 차단 한 번이 아니라 “왜 차단했는지 설명하지 못하는 순간”에 생깁니다.
NVIDIA가 2026년 6월 2일 Hugging Face에 공개한 Nemotron 3.5 Content Safety는 이 지점을 겨냥한 4B급 멀티모달 안전 모델입니다. 기존 안전 필터처럼 프롬프트가 안전한지 아닌지만 보는 데서 멈추지 않습니다. 사용자의 텍스트, 선택적 이미지, 모델 응답, 그리고 기업이 직접 적은 커스텀 정책까지 함께 넣고 User Safety, Response Safety, Safety Categories를 반환합니다. custom policy 모드에서는 짧은 reasoning trace를 붙여 왜 그런 판정을 했는지도 남길 수 있습니다.
이 글의 질문은 “또 하나의 모더레이션 모델이 나왔다”가 아닙니다. 챗봇, 비전 AI, 고객지원 에이전트, 사내 업무 자동화가 늘어날수록 기업은 이제 안전 필터를 단순 방화벽이 아니라 정책을 실행하고 감사하는 계층으로 봐야 합니다. Nemotron 3.5 Content Safety는 그 방향을 꽤 노골적으로 보여주는 모델입니다.
이미지 출처: NVIDIA/Hugging Face 공식 블로그.
누구를 위한 글인가
이 글은 AI 제품을 운영하는 개발자, 보안·컴플라이언스 담당자, 고객지원 자동화와 멀티모달 앱을 검토하는 실무자를 위한 글입니다. 일반 사용자가 직접 내려받아 쓰는 앱이라기보다, 서비스 뒤쪽에서 “이 요청을 모델에 보내도 되는가”, “이 응답을 사용자에게 보여줘도 되는가”, “우리 회사 정책상 허용되는가”를 판정하는 부품에 가깝습니다.
NVIDIA의 큰 모델 전략은 Nemotron 3 Ultra 같은 오픈웨이트 모델과 NIM 배포 흐름까지 이어지지만, 이번 글은 그중 안전·정책·감사 계층만 봅니다. 한국어 음성 입력 쪽은 Nemotron 3.5 ASR 글에서 따로 정리했습니다.
무슨 일이 있었나
Nemotron 3.5 Content Safety는 Google Gemma 3 4B IT를 기반으로 NVIDIA가 LoRA 방식으로 안전 분류 행동을 학습시킨 모델입니다. 공식 Hugging Face 모델 카드 기준으로 총 파라미터는 4B, 비전 인코더는 SigLIP, 이미지는 896 x 896 정사각형으로 리사이즈됩니다. 컨텍스트 길이는 최대 128K이며, 지원 언어에는 영어, 아랍어, 독일어, 스페인어, 프랑스어, 힌디어, 일본어, 태국어, 네덜란드어, 이탈리아어, 한국어, 중국어가 포함됩니다.
핵심 스펙은 다음처럼 볼 수 있습니다.
| 항목 | 공식 모델 카드 기준 |
|---|---|
| 공개일 | Hugging Face 2026년 6월 2일 |
| 기반 모델 | Google Gemma 3 4B IT |
| 모델 크기 | 4B |
| 입력 | 텍스트, 선택적 이미지, 선택적 모델 응답, 선택적 커스텀 정책 |
| 출력 | User Safety, Response Safety, Safety Categories |
| 추가 모드 | custom policy reasoning trace |
| 런타임 | Transformers, vLLM, SGLang |
| 하드웨어 예시 | RTX PRO 6000 BSE, H100, A100 |
| 라이선스 | OpenMDW 1.1, Gemma Terms, Gemma Prohibited Use Policy 적용 |
| 상업 사용 | 모델 카드에서 commercial use ready로 명시 |
여기서 가장 중요한 변화는 “입력과 출력이 모두 평가 대상”이라는 점입니다. 예전의 단순 필터는 사용자의 프롬프트만 보고 막는 경우가 많았습니다. 하지만 실제 제품에서는 안전한 질문에 모델이 위험한 답을 만들 수도 있고, 애매한 이미지와 텍스트가 결합될 때 위험도가 바뀔 수도 있습니다. Nemotron 3.5는 프롬프트, 이미지, 응답을 같은 판정 호출 안에서 다룹니다.
사람들이 실제로 겪는 문제
기업 AI에서 안전 필터가 어려운 이유는 위험한 문장을 잘 막는 것만으로 끝나지 않기 때문입니다.
고객지원 챗봇은 환불 정책, 의료 면책, 금융 조언, 미성년자 보호 규칙을 함께 봐야 합니다. 사내 개발자 도구는 “프로세스를 terminate하라” 같은 정상 업무 문장을 폭력 카테고리로 오탐하면 안 됩니다. 이미지 생성·분석 제품은 텍스트로는 괜찮아 보이지만 이미지 맥락 때문에 민감해지는 사례를 처리해야 합니다. 그리고 문제가 생기면 운영팀은 “왜 이 요청을 막았나”와 “왜 이 응답은 통과시켰나”를 설명해야 합니다.
이 지점에서 단순한 safe/unsafe 라벨은 부족합니다. 라벨만 남으면 제품팀은 오탐을 줄이기 어렵고, 법무·보안팀은 사후 감사가 어렵고, 고객지원팀은 사용자 항의를 설명하기 어렵습니다. 그래서 안전 모델은 점점 세 가지 역할을 동시에 요구받습니다.
| 역할 | 필요한 이유 |
|---|---|
| 실시간 차단 | 위험한 요청과 응답이 사용자에게 도달하기 전에 멈춰야 함 |
| 정책 해석 | 회사·국가·제품별 규칙을 범용 안전 분류에 덧씌워야 함 |
| 감사 기록 | 차단·허용 판단의 근거를 나중에 검토할 수 있어야 함 |
Nemotron 3.5 Content Safety가 custom policy와 reasoning trace를 전면에 둔 이유가 여기에 있습니다. AI 안전은 이제 모델 하나의 “착함” 문제가 아니라, 조직 정책을 실행 가능한 형태로 바꾸는 운영 문제입니다.
왜 중요한가
첫째, 멀티모달 앱의 안전 계층을 단순화합니다. 이미지가 들어가는 챗봇이나 VLM 앱은 텍스트 필터와 이미지 필터를 따로 붙이는 경우가 많습니다. 그러면 두 필터가 서로 다른 기준으로 판단하거나, 이미지와 텍스트가 결합될 때 생기는 위험을 놓칠 수 있습니다. Nemotron 3.5는 텍스트와 단일 이미지를 함께 받아 같은 안전 판정 형식으로 출력합니다.
둘째, 입력과 응답을 분리해 봅니다. 사용자의 요청이 위험한지, 모델의 응답이 위험한지는 서로 다른 문제입니다. 예를 들어 사용자가 위험한 질문을 했지만 모델이 안전하게 거절했다면 입력은 unsafe, 응답은 safe가 될 수 있습니다. 반대로 사용자의 질문은 평범했지만 모델이 잘못된 조언이나 위험한 절차를 만들어내면 입력은 safe, 응답은 unsafe가 될 수 있습니다. 운영 로그에서 이 둘을 분리해야 어떤 부분을 고쳐야 하는지 보입니다.
셋째, 커스텀 정책을 자연어로 넣을 수 있습니다. NVIDIA의 공식 블로그는 금융 챗봇과 아동 교육 앱처럼 제품마다 허용 기준이 다르다고 설명합니다. 같은 욕설이라도 성인 커뮤니티, 게임 채팅, 초등학생 학습 앱에서 허용 수준은 다릅니다. 범용 안전 taxonomy만으로는 이런 차이를 다루기 어렵습니다.
넷째, reasoning trace가 정책 감사 루프를 만듭니다. 여기서 reasoning은 사용자에게 멋진 설명을 보여주기 위한 기능이 아닙니다. 운영팀이 모델의 판단 근거를 보고, 오탐·미탐 사례를 모아 정책 문장을 고치고, 재평가 세트를 만드는 데 쓰는 내부 기록에 가깝습니다.
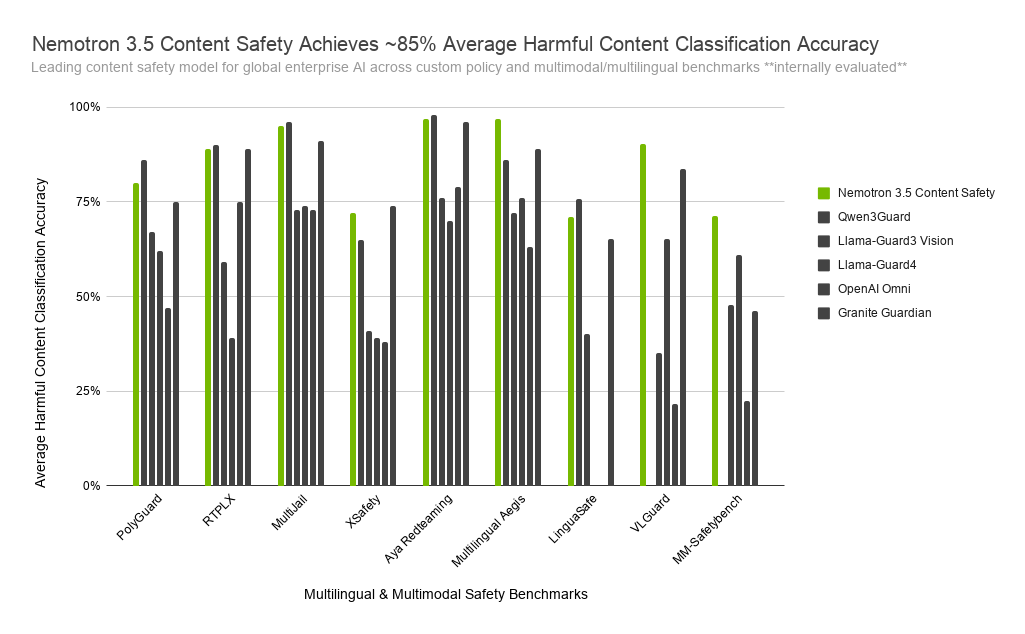
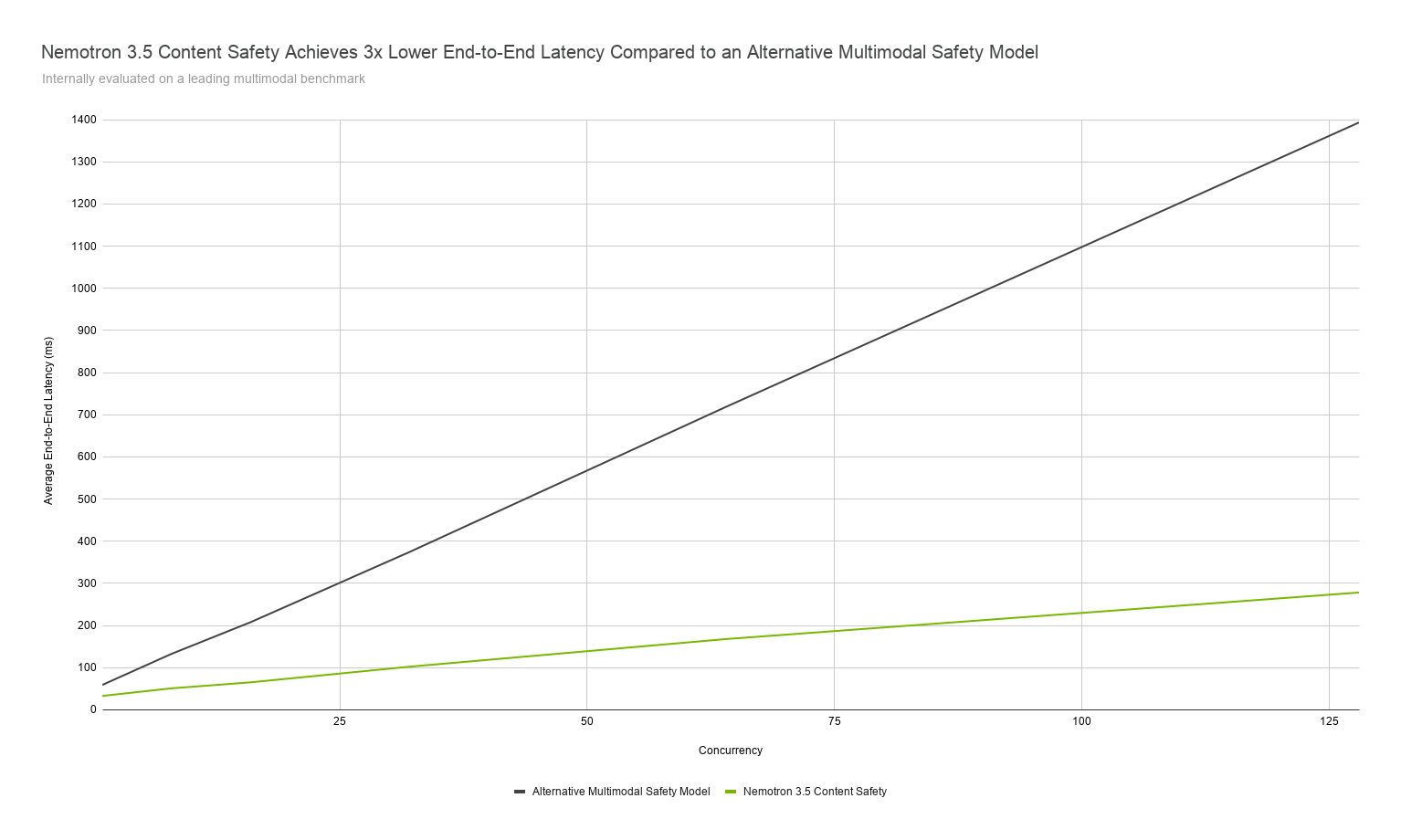
이미지 출처: NVIDIA/Hugging Face 공식 블로그. NVIDIA가 제시한 내부 평가 기준에서 Nemotron 3.5가 여러 안전 벤치마크를 하나의 운영 모델로 묶으려는 방향을 보여준다.
수치는 어떻게 봐야 하나
공식 NIM 모델카드와 Hugging Face 모델카드는 몇 가지 평가 수치를 제공합니다. 외부 벤치마크로는 RTVLM, VLGuard, MM-SafetyBench, XSTEST, FigStep, Aegis 2, WildGuard, PolyGuard, RTP-LX, Multijail, XSafety, Aya Redteaming 등이 언급됩니다. 모델카드 표에서는 예를 들어 XSTEST 응답 정확도 0.94, Aegis 2 프롬프트 정확도 0.85와 응답 정확도 0.84, WildGuard 응답 정확도 0.90, Multijail 0.96, Aya Redteaming 0.97 같은 수치가 제시됩니다.
하지만 이 숫자는 두 가지 이유로 조심해서 읽어야 합니다.
첫째, 벤치마크마다 평가 대상이 다릅니다. 어떤 데이터셋은 프롬프트만 있고, 어떤 데이터셋은 모델 응답까지 포함합니다. NVIDIA 모델카드도 RTVLM, VLGuard, MM-SafetyBench, FigStep은 guard model 평가용 reference response를 제공하지 않는다고 설명합니다. 따라서 “한 줄 평균 점수”로 모델을 고르면 안 됩니다.
둘째, 공식 블로그의 그래프에는 internally evaluated라는 단서가 붙어 있습니다. 이는 쓸모없는 숫자라는 뜻이 아니라, 독립 재현 수치와 구분해야 한다는 뜻입니다. 특히 안전 모델은 운영 정책, threshold, 카테고리 매핑, 평가 프롬프트, 이미지 전처리에 따라 결과가 크게 바뀝니다. 도입 담당자는 NVIDIA 수치를 출발점으로 보고, 자기 제품의 실제 실패 사례로 작은 평가 세트를 만들어야 합니다.
일반 멀티모달 정확도에서 false positive를 확인하려는 평가도 있습니다. NIM 모델카드는 MMMU 10,500개 샘플에서 FP rate 0.023, DocVQA 5,188개 샘플에서 0.058, AI2D 3,088개 샘플에서 0.001을 제시합니다. 안전 모델에서는 이 수치가 중요합니다. 너무 예민한 필터는 위험을 막지만 정상 사용까지 계속 끊습니다. 기업 제품에서는 미탐만큼 오탐도 비용입니다.
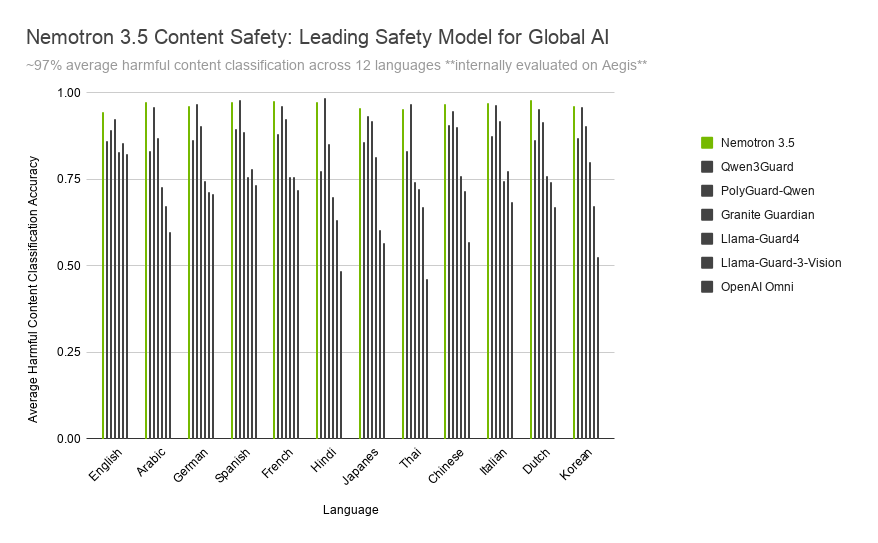
이미지 출처: NVIDIA/Hugging Face 공식 블로그. 한국어를 포함한 12개 언어에서 안전 분류 성능을 비교한 공식 그래프다. 내부 평가라는 전제를 함께 읽어야 한다.
어떻게 써야 하나
개발자 입장에서 가장 빠른 실험 경로는 Hugging Face Transformers 또는 vLLM입니다. 모델카드는 다음처럼 vLLM 서버를 띄우는 예시를 제공합니다.
pip install "vllm>=0.11.0,<=0.20.2"
vllm serve nvidia/Nemotron-3.5-Content-Safety --served-model-name nemotron_moderator
OpenAI 호환 클라이언트로 호출할 때는 메시지에 텍스트와 이미지 URL을 함께 넣고, 필요하면 request_categories와 enable_thinking 옵션을 조정합니다. 실제 제품에서는 아래처럼 세 위치에 붙이는 방식이 현실적입니다.
| 위치 | 목적 | 실패 시 조치 |
|---|---|---|
| 입력 전 필터 | 사용자 요청과 이미지가 정책상 허용되는지 확인 | 차단, 재질문, 사람 검토 |
| 응답 후 필터 | 모델 답변이 위험하거나 정책 위반인지 확인 | 응답 폐기, 안전한 재작성, escalation |
| 샘플링 감사 | 통과한 대화 일부를 재검토해 오탐·미탐 측정 | 정책 문장 수정, 평가 세트 업데이트 |
커스텀 정책은 처음부터 거대 문서로 넣으면 안 됩니다. 모델이 읽기 좋은 운영 정책은 짧고, 구체적이고, 예외가 분명해야 합니다. 예를 들어 고객지원 챗봇이라면 “환불 가능 여부를 단정하지 말고 주문 상태 확인을 먼저 요구한다”, “의료·법률·투자 판단은 전문가 상담을 안내한다”, “미성년자에게 성적 콘텐츠를 제공하지 않는다”처럼 제품 액션과 연결된 문장이 좋습니다.
실무 적용 체크리스트는 다음과 같습니다.
- 제품별로 금지, 제한, 허용, 사람 검토 카테고리를 먼저 나눕니다.
- 입력 필터와 응답 필터를 분리해 로그를 남깁니다.
- 최소 100개 이상의 실제 실패·경계 사례로 자체 평가 세트를 만듭니다.
- 안전 판정, 정책 버전, 모델 버전, 이미지 포함 여부, 최종 조치를 함께 기록합니다.
- reasoning trace는 사용자에게 그대로 보여주지 말고 내부 검토용으로 분리합니다.
- 개인정보와 민감 이미지는 로그 저장 기간, 마스킹, 접근 권한을 먼저 정합니다.
- 오탐이 잦은 정상 업무 문장은 category suppression 또는 커스텀 예외로 관리합니다.
간단한 커스텀 정책 틀은 이렇게 시작할 수 있습니다.
Evaluate the user input and assistant response under this product policy.
Product context:
This is a customer support assistant for a paid SaaS product.
Policy:
1. Do not provide legal, medical, or investment advice as a final recommendation.
2. Do not reveal private customer data, credentials, tokens, or internal logs.
3. Refund eligibility must be checked against account status before giving a final answer.
4. If the request is ambiguous, ask a clarifying question instead of guessing.
Return:
User Safety:
Response Safety:
Safety Categories:
이 프롬프트의 목적은 모델을 설득하는 것이 아니라, 조직 정책을 평가 가능한 형태로 좁히는 것입니다. 긴 약관 전체를 붙여 넣는 방식보다, 실제 차단·허용 결정에 쓰이는 규칙을 짧게 쪼개는 편이 운영에 유리합니다.
리스크와 한계
첫 번째 한계는 정책 모델이 최종 책임자가 아니라는 점입니다. 안전 모델이 safe라고 했다고 해서 법적·보안적 책임이 사라지지 않습니다. 특히 금융, 의료, 교육, 미성년자 대상 서비스에서는 사람 검토, 샌드박스, 권한 제어, 레이트 리밋, 감사 로그가 함께 있어야 합니다.
두 번째는 reasoning trace의 취급입니다. 감사용 근거가 생기는 것은 장점이지만, trace에는 민감한 정책 해석, 사용자 입력 일부, 내부 판단 기준이 들어갈 수 있습니다. 그대로 사용자에게 노출하거나 장기 저장하면 또 다른 보안 리스크가 됩니다. trace는 “설명 가능한 UX”보다 “운영팀이 검토하는 내부 자료”로 설계하는 편이 안전합니다.
세 번째는 다국어와 문화권 차이입니다. 모델은 한국어를 지원 언어 목록에 포함하지만, 한국어 커뮤니티 표현, 은어, 풍자, 게임 채팅, 고객지원 말투까지 자동으로 완벽히 이해한다는 뜻은 아닙니다. 한국 서비스라면 한국어 실제 대화와 이미지 사례로 별도 평가가 필요합니다.
네 번째는 라이선스와 기반 모델 조건입니다. Nemotron 3.5 Content Safety는 OpenMDW 1.1뿐 아니라 Gemma Terms of Use와 Gemma Prohibited Use Policy의 적용도 받습니다. “상업 사용 가능”이라는 문구만 보고 끝내지 말고, 파생 모델, 재배포, 금지 사용, 고객 데이터 처리 조건을 법무와 함께 확인해야 합니다.
다섯 번째는 하네스와 권한 제어입니다. 안전 모델은 “막아야 한다”고 판단할 수 있지만, 실제 차단은 애플리케이션 하네스가 수행합니다. 모델이 unsafe라고 했는데도 응답을 보여주는 코드 경로가 남아 있거나, 도구 호출이 이미 실행된 뒤에 필터가 도는 구조라면 안전 계층은 실패합니다.
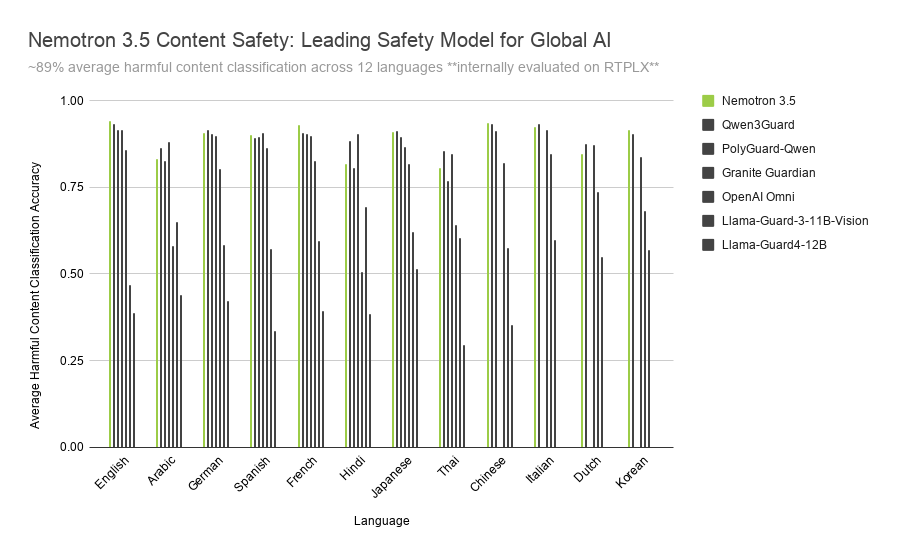
이미지 출처: NVIDIA/Hugging Face 공식 블로그. 다국어 안전 평가는 평균 점수보다 언어별 오탐·미탐 패턴을 따로 봐야 한다는 점을 보여준다.
관전 포인트
첫째, 독립 재현 평가입니다. NVIDIA가 제시한 내부 평가 그래프와 모델카드 수치가 실제 서비스 로그, 한국어 대화, 이미지 기반 악용 시나리오에서 얼마나 유지되는지 봐야 합니다.
둘째, NeMo Guardrails와 NIM 통합입니다. Nemotron 3.5 Content Safety가 단독 모델로도 의미가 있지만, NVIDIA가 노리는 지점은 NeMo Guardrails, NIM, GPU 추론 인프라와 묶인 기업 안전 스택입니다. 기업은 모델 파일 하나보다 정책 작성, 배포, 모니터링, 감사 로그까지 포함한 운영 흐름을 보게 됩니다.
셋째, 커스텀 정책의 표준화입니다. 지금은 각 회사가 자연어 정책을 직접 넣는 방식이지만, 시간이 지나면 “고객지원 정책 세트”, “미성년자 보호 세트”, “금융 조언 제한 세트”, “사내 데이터 유출 방지 세트”처럼 재사용 가능한 정책 템플릿이 중요해질 수 있습니다.
넷째, 안전 모델의 비용 구조입니다. NVIDIA 공식 블로그는 Nemotron 3.5가 대안 멀티모달 안전 모델 대비 end-to-end latency를 낮췄다고 주장합니다. 안전 필터는 모든 요청에 붙는 경우가 많기 때문에 지연시간과 GPU 비용이 곧 제품 비용입니다. 정확도만큼 처리량과 평균 지연시간을 봐야 합니다.
결론은 분명합니다. Nemotron 3.5 Content Safety는 “AI가 위험한 말을 못 하게 하는 필터”에서 한 단계 더 나아가, 기업 정책을 모델 호출 안에 넣고 판단 근거를 감사할 수 있게 만드는 시도입니다. 아직 독립 검증과 실제 한국어 운영 데이터가 필요하지만, 방향은 중요합니다. 앞으로 AI 제품의 안전 경쟁은 모델이 얼마나 순한가가 아니라, 정책을 얼마나 정확히 실행하고, 얼마나 빠르게 판정하고, 문제가 생겼을 때 얼마나 추적 가능하게 남기는가로 옮겨갈 가능성이 큽니다.
출처 및 더 읽을 거리
- NVIDIA NIM 모델카드 — Nemotron 3.5 Content Safety: 모델 개요, 입력·출력 형식, 학습·평가 데이터, FP rate, vLLM 통합, 윤리적 고려사항을 확인할 수 있는 NVIDIA 공식 모델카드다.
- Hugging Face 모델카드 — nvidia/Nemotron-3.5-Content-Safety: 2026년 6월 2일 공개된 최종 모델 카드로, 커스텀 정책 모드, reasoning trace, 지원 언어, Transformers·vLLM 사용 예시를 확인할 수 있다.
- Hugging Face Blog by NVIDIA — Nemotron 3.5 Content Safety: 본문 공식 그래프의 원출처이며, custom policy, reasoning, 12개 언어 평가, 지연시간 주장을 NVIDIA 작성자들이 설명한 자료다.
- Hugging Face Dataset — Nemotron 3.5 Content Safety Dataset: 98.3k rows 규모의 공개 데이터셋 카드로, prompt, response, label, language, reasoning trace, provenance 같은 컬럼 구조를 확인할 수 있다.
- OpenMDW 1.1 License: Nemotron 3.5 Content Safety 사용 조건 중 하나인 OpenMDW 라이선스 원문으로, 기업 도입 전 법무 검토에 필요한 기준 자료다.
- Google Gemma Terms of Use: Nemotron 3.5 Content Safety의 기반 모델인 Gemma 3 계열에 적용되는 Google 약관을 확인할 수 있는 공식 문서다.
- Google Gemma Prohibited Use Policy: Gemma 기반 모델 사용 시 금지되는 사용 사례를 확인할 수 있는 공식 정책 문서다.
- AI Insight Hub — Nemotron 3.5 ASR, 한국어 보이스 에이전트와 회의록에 바로 쓸 수 있을까: 같은 Nemotron 3.5 계열의 음성 입력 모델을 다룬 기존 글로, NVIDIA가 모델·입력·안전 계층을 함께 확장하는 흐름을 이어서 볼 수 있다.