
핵심 요약
한국어 회의록 AI에서 가장 비싼 구간은 요약이 아니라 “말을 텍스트로 바꾸는 첫 1초”일 수 있습니다.
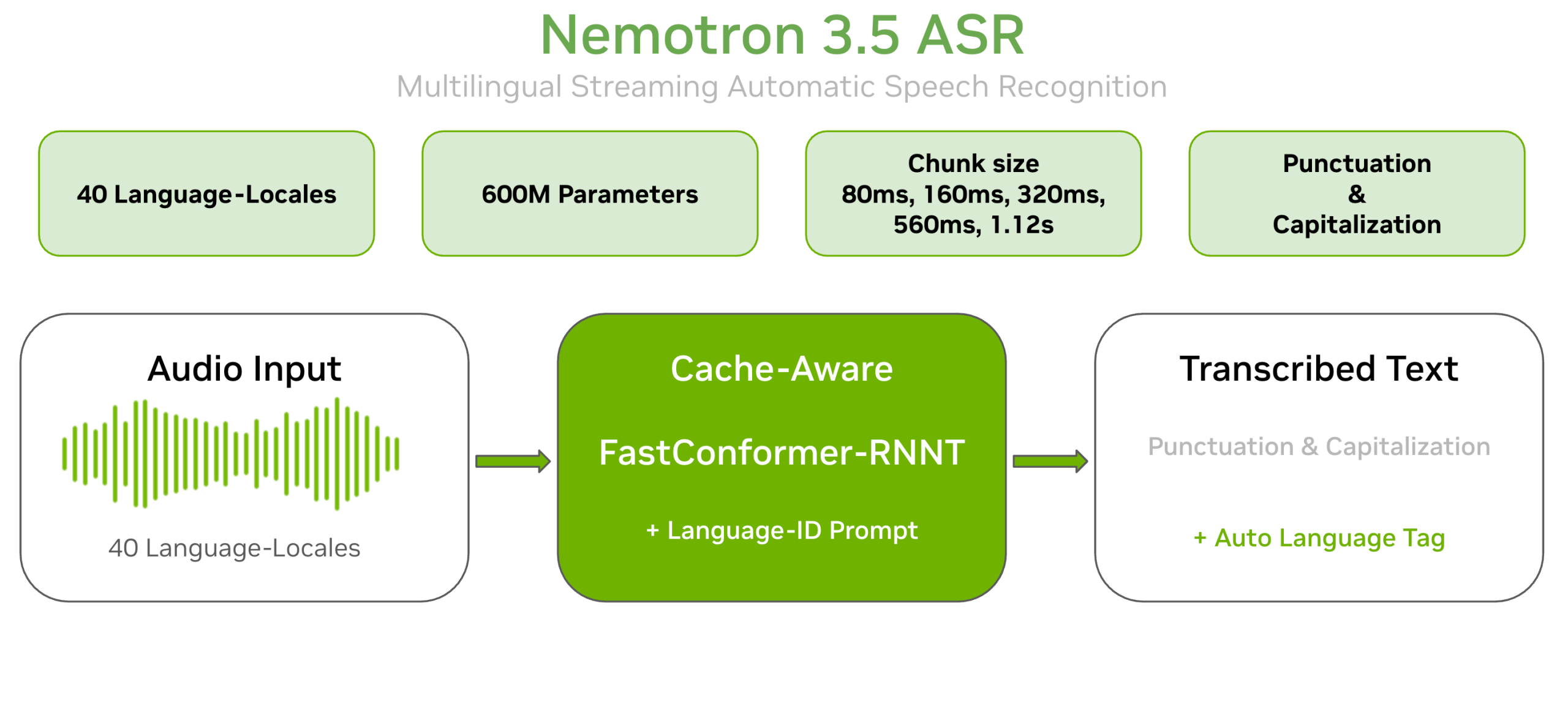
NVIDIA가 2026년 6월 4일 Hugging Face에 공개한 Nemotron 3.5 ASR은 이 첫 구간을 겨냥한 다국어 스트리밍 음성인식 모델입니다. 모델 크기는 600M 파라미터, 지원 범위는 40개 언어 로케일, 한국어는 바로 전사에 쓸 수 있는 transcription-ready 티어에 들어갑니다. 공식 모델 카드 기준으로 한국어 FLEURS 테스트에서 320ms 청크 LangID 설정 CER 7.27%, 1.12초 청크 LangID 설정 CER 7.12%를 기록했습니다. 한국어와 일본어는 단어 오류율 WER이 아니라 문자 오류율 CER로 평가했다는 점도 함께 봐야 합니다.
이 글의 질문은 “새 음성인식 모델이 나왔다”가 아닙니다. 한국어 회의록, 고객 상담, 실시간 보이스 에이전트를 만들 때 이제 API 하나에만 묶이지 않고 오픈웨이트 ASR을 직접 운영할 선택지가 얼마나 현실적이 됐는가입니다.
이미지 출처: NVIDIA Hugging Face 모델 카드.
누구를 위한 글인가
이 글은 한국어 회의록 도구, 콜센터 상담 분석, 음성 명령 앱, 실시간 자막, 보이스 에이전트를 검토하는 개발자와 실무자를 위한 글입니다. 모델 구조 자체보다 중요한 질문은 네 가지입니다.
- 한국어를 바로 지원하는가.
- 실시간 대화에서 체감 지연이 낮은가.
- 운영비를 줄일 여지가 있는가.
- 사내 데이터와 음성을 외부 API로 보내지 않고 운영할 수 있는가.
일반 사용자 입장에서는 “내 회의 녹음이 더 정확해질까”가 핵심이고, 개발자 입장에서는 “ASR → LLM → TTS 루프에서 병목이 줄어드나”가 핵심입니다. 두 질문은 연결되어 있습니다. 음성인식이 늦거나 틀리면 뒤의 요약 모델이 아무리 좋아도 회의록과 보이스 에이전트 경험은 무너집니다.
무슨 일이 있었나
Nemotron 3.5 ASR은 NVIDIA의 영어 전용 Nemotron Speech Streaming 모델을 다국어로 확장한 모델입니다. 공식 설명에 따르면 단일 체크포인트가 40개 언어 로케일을 처리하고, 언어 ID 프롬프트를 넣어 특정 언어로 전사하거나 target_lang=auto로 자동 언어 감지를 맡길 수 있습니다.
핵심 스펙을 표로 압축하면 이렇습니다.
| 항목 | Nemotron 3.5 ASR 공식 설명 기준 |
|---|---|
| 공개일 | 2026년 6월 4일, Hugging Face |
| 모델 크기 | 600M 파라미터 |
| 구조 | Cache-Aware FastConformer-RNNT, 언어 ID 프롬프트 조건부 |
| 지원 범위 | 40개 언어 로케일 |
| 한국어 | transcription-ready 티어, ko-KR |
| 출력 | 입력 언어 텍스트, 문장부호와 대소문자 지원 |
| 스트리밍 설정 | 80ms, 160ms, 320ms, 560ms, 1.12초 청크 |
| 실행 프레임워크 | NVIDIA NeMo 26.06 이상 |
| 라이선스 | OpenMDW-1.1 |
여기서 눈에 띄는 부분은 한국어가 “나중에 fine-tuning하면 쓸 수 있음”이 아니라 transcription-ready로 분류됐다는 점입니다. 같은 모델 카드에서 broad-coverage, adaptation-ready 언어를 따로 구분하는데, 한국어는 영어·일본어·독일어·베트남어 등과 함께 바로 전사 가능한 상위 티어에 들어갑니다.
Nemotron 3.5 ASR은 NVIDIA의 거대 언어모델 발표와 같은 방향의 움직임입니다. NVIDIA는 이제 GPU만 파는 회사가 아니라, 모델·NeMo·NIM·배포 파트너까지 묶어 기업 AI 스택을 직접 제안하고 있습니다. ASR은 그중 사용자의 음성을 시스템으로 들여오는 입구입니다.
사람들이 실제로 겪는 문제
한국어 회의록과 상담 녹취에서 문제는 “AI가 요약을 못한다”보다 앞단에 있는 경우가 많습니다.
회의실에서 녹음하면 발화자는 멀리 있고, 노트북 팬 소리와 키보드 소리가 섞이고, 참석자가 서로 말을 겹칩니다. 콜센터 녹취는 전화망 압축, 주변 소음, 빠른 말투, 지역 억양, 상품명과 숫자 때문에 오류가 납니다. 보이스 에이전트는 여기에 더해 실시간성이 붙습니다. 사용자가 “내일 오전 10시에 김민수 팀장에게 회의 잡아줘”라고 말했는데 이름이나 시간이 틀리면, 뒤의 에이전트는 잘못된 도구 호출을 할 수 있습니다.
이 때문에 음성 AI 제품은 세 층으로 나눠 봐야 합니다.
| 층 | 실패하면 생기는 문제 |
|---|---|
| ASR | 말 자체를 잘못 받아 적어 이름, 숫자, 제품명이 틀림 |
| LLM 요약·추론 | 잘 받아 적은 텍스트를 잘못 요약하거나 없는 결론을 만듦 |
| 도구 실행 | 잘못된 일정 생성, 메일 발송, CRM 기록 같은 실제 행동으로 이어짐 |
지난번 Mega-ASR 회의 녹음 글에서는 잡음 많은 녹음 파일을 어디까지 살릴 수 있는지가 핵심이었습니다. Nemotron 3.5 ASR의 포인트는 조금 다릅니다. 녹음 파일을 나중에 배치로 처리하는 것보다, 말이 들어오는 동안 바로 텍스트로 만들고 다음 AI 단계로 넘기는 운영 구조에 더 가깝습니다.
왜 중요한가
Nemotron 3.5 ASR의 의미는 “한국어도 된다”에서 끝나지 않습니다. 세 가지가 더 중요합니다.
첫째, 스트리밍 지연을 설정으로 고를 수 있습니다. 공식 모델 카드는 att_context_size의 오른쪽 컨텍스트 값을 바꿔 80ms, 160ms, 320ms, 560ms, 1.12초 청크를 선택할 수 있다고 설명합니다. 짧은 청크는 반응이 빠르지만 정확도에서 손해를 볼 수 있고, 긴 청크는 정확도가 조금 나아지는 대신 지연이 늘어납니다.
둘째, 캐시 인식 구조가 운영비와 연결됩니다. 일반적인 buffered streaming은 겹치는 오디오 구간을 반복 계산합니다. Nemotron 3.5 ASR은 self-attention과 convolution 레이어의 캐시를 유지해 새 프레임만 처리하는 구조를 씁니다. NVIDIA는 단일 H100 기준 80ms 설정에서 Nemotron이 240개 동시 실시간 스트림을 처리하는 반면, 비교 대상 Parakeet RNNT 1.1B multilingual buffered 모델은 14개라고 밝혔습니다. 1.12초 설정에서는 2,400개 대 400개입니다.
셋째, 오픈웨이트와 자체 배포가 보안 검토의 선택지를 넓힙니다. 회의록과 상담 녹취는 개인 정보, 고객 정보, 영업 전략, 법무 리스크가 섞이는 데이터입니다. 외부 API가 항상 나쁘다는 뜻은 아니지만, 금융·의료·제조·공공 조직에서는 음성 데이터를 어디로 보내는지가 도입의 첫 관문입니다. Nemotron 3.5 ASR은 Hugging Face 모델 카드와 NeMo 경로를 통해 직접 실행·fine-tuning을 검토할 수 있는 쪽에 놓여 있습니다.
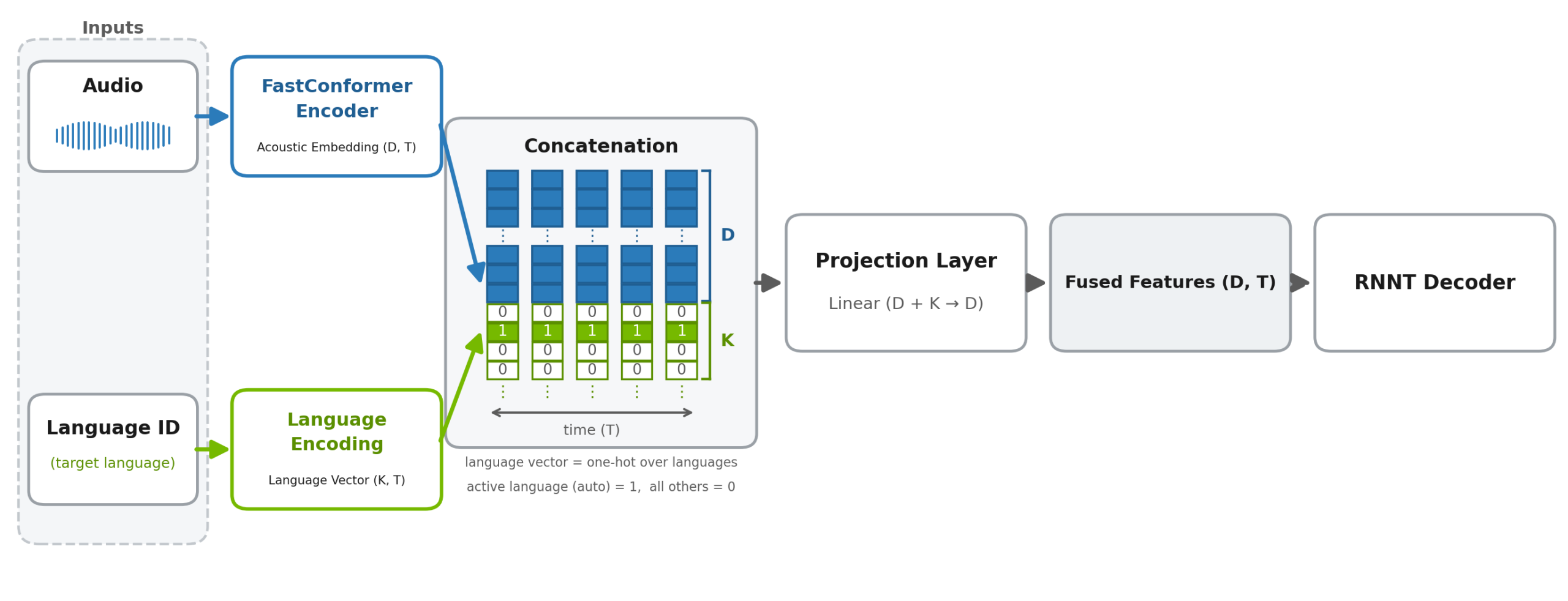
이미지 출처: NVIDIA Hugging Face 모델 카드. 언어 ID 프롬프트가 단순 라벨이 아니라 음향 표현과 결합되어 다국어 전사를 조건화하는 구조를 보여주는 공식 그림이다.
한국어 수치는 어떻게 봐야 하나
공식 모델 카드의 한국어 수치는 꽤 구체적입니다. FLEURS 테스트 기준, 한국어는 CER로 평가됐습니다.
한국어 ko-KR 설정 |
80ms | 160ms | 320ms | 560ms | 1.12초 |
|---|---|---|---|---|---|
| LangID 입력 | 7.59 | 7.70 | 7.27 | 7.18 | 7.12 |
| Auto-detect | 8.31 | 8.18 | 7.81 | 7.49 | 7.30 |
이 표에서 실무자가 봐야 할 포인트는 두 가지입니다.
하나는 한국어에서 target_lang=ko-KR처럼 언어를 명시하는 편이 자동 감지보다 대체로 낫다는 점입니다. 회의록 도구나 사내 콜센터처럼 언어를 이미 알고 있다면 auto를 기본값으로 둘 이유가 별로 없습니다. 반대로 글로벌 고객지원처럼 영어와 한국어가 섞일 수 있는 채널에서는 자동 감지가 운영 편의성을 줄 수 있습니다.
다른 하나는 320ms와 1.12초의 차이가 숫자상 크지 않다는 점입니다. 한국어 LangID 기준 CER은 320ms 7.27%, 1.12초 7.12%입니다. 보이스 에이전트라면 320ms 전후를 먼저 테스트하고, 법무 회의록이나 상담 품질 평가처럼 정확도가 더 중요한 배치 처리에서는 560ms나 1.12초를 검토하는 식이 현실적입니다.
다만 이 수치를 제품 품질로 바로 번역하면 안 됩니다. 공식 모델 카드도 텍스트 정규화가 완벽하지 않아 보고된 WER/CER이 실제 체감 품질보다 다소 높게 나올 수 있다고 설명합니다. 반대로 FLEURS는 표준 벤치마크이고, 실제 한국어 회의실의 겹침 발화, 사투리, 마이크 품질, 사내 약어, 사람 이름은 별도 테스트가 필요합니다.
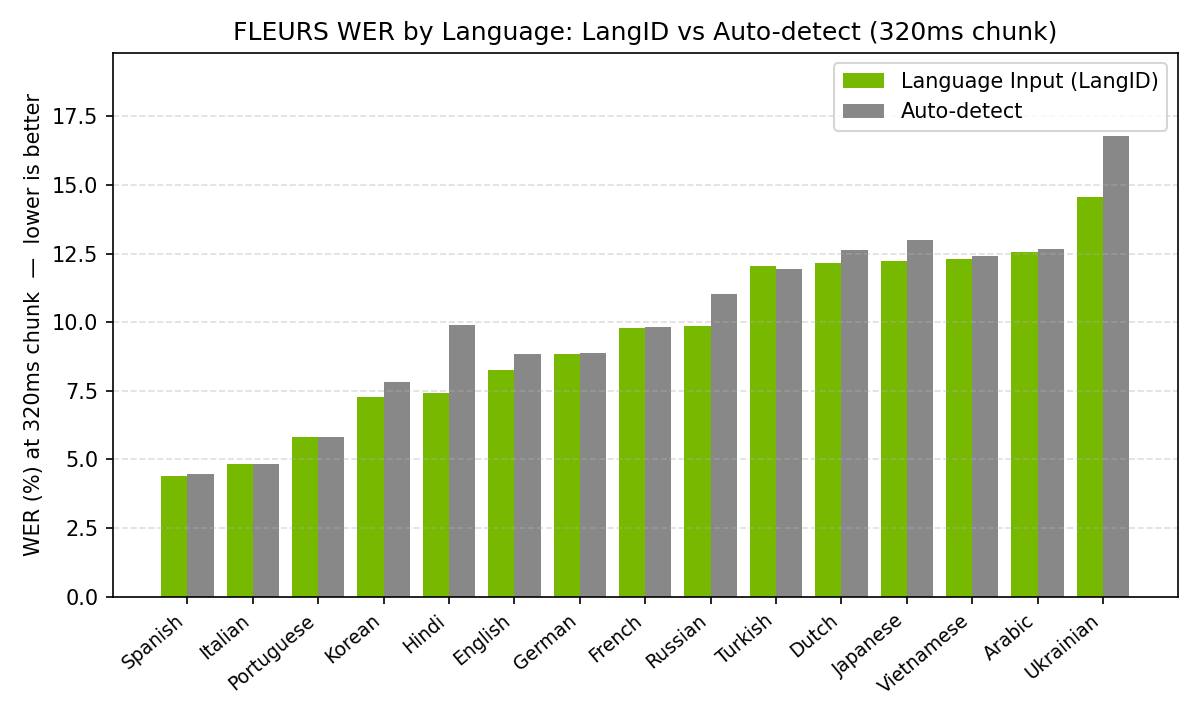
이미지 출처: NVIDIA Hugging Face 모델 카드. 한국어는 WER가 아니라 CER로 측정됐고, 언어를 지정한 경우와 자동 감지한 경우의 차이를 확인할 수 있다.
어떻게 써야 하나
당장 실험해 볼 개발자는 NeMo 경로를 보면 됩니다. 공식 모델 카드는 사전학습 체크포인트를 불러오는 가장 짧은 예시를 이렇게 제시합니다.
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(
model_name="nvidia/nemotron-3.5-asr-streaming-0.6b"
)
transcriptions = asr_model.transcribe(["file.wav"])
스트리밍 추론은 NeMo의 cache-aware streaming inference 스크립트를 사용합니다. 한국어 회의록 실험이라면 target_lang=ko-KR로 고정하고, 오디오 파일은 mono-channel .wav로 맞추는 것이 출발점입니다.
cd NeMo
python examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=<model_path> \
dataset_manifest=<dataset_manifest> \
batch_size=<batch_size> \
target_lang=ko-KR \
att_context_size="[56,3]" \
strip_lang_tags=true \
output_path=<output_folder>
여기서 [56,3]은 320ms 청크에 해당합니다. 가장 빠른 응답이 필요하면 [56,0]으로 80ms를, 정확도를 조금 더 보려면 [56,6] 또는 [56,13]을 비교하면 됩니다. 자동 언어 감지가 필요한 서비스라면 target_lang=auto와 strip_lang_tags=false를 함께 테스트해 출력 끝의 언어 태그를 로그로 남기는 방식도 가능합니다.
실무 적용 기준은 아래처럼 잡는 편이 안전합니다.
| 사용 사례 | 우선 설정 | 이유 |
|---|---|---|
| 실시간 보이스 에이전트 | 160ms 또는 320ms, ko-KR |
사용자가 기다리는 시간을 줄이되 한국어 정확도를 유지해야 함 |
| 회의 중 실시간 자막 | 320ms 또는 560ms, ko-KR |
지연과 가독성의 균형이 중요함 |
| 회의 종료 후 회의록 | 560ms 또는 1.12초, ko-KR |
실시간성보다 이름·숫자·결정사항 보존이 중요함 |
| 다국어 고객지원 | 320ms, auto와 언어 태그 유지 |
통화 중 언어 전환과 채널 분류가 필요할 수 있음 |
| 사내 전문 용어가 많은 조직 | 기본 모델 테스트 후 fine-tuning | 제품명, 사람 이름, 약어는 범용 모델에서 흔히 틀림 |
체크리스트도 단순합니다.
- 최소 50개 이상의 실제 한국어 음성 샘플로 자체 CER/WER를 재세요.
- 사람 이름, 회사명, 제품명, 숫자, 날짜만 따로 오류율을 보세요.
- 회의실 원거리 마이크, 이어폰 마이크, 전화 녹취를 분리해서 평가하세요.
- ASR 원문과 LLM 요약을 따로 채점하세요. 요약이 틀렸는지, 전사가 틀렸는지를 섞으면 개선 방향을 잃습니다.
- 보이스 에이전트는 도구 호출 전 “제가 이해한 내용은…” 확인 단계를 넣으세요.
- 고객 정보와 사내 회의 음성은 저장 위치, 로그 보존 기간, 재학습 사용 여부를 먼저 정하세요.
리스크와 한계
Nemotron 3.5 ASR이 바로 모든 한국어 회의록 문제를 해결한다고 보기는 어렵습니다.
첫 번째 한계는 화자 분리입니다. ASR은 말을 텍스트로 바꾸는 모델이고, “누가 말했는가”는 별도의 diarization 문제가 됩니다. 회의록 제품에는 보통 음성 구간 분리, 화자 분리, 발화 병합, 요약, 액션 아이템 추출이 함께 필요합니다. Nemotron 3.5 ASR은 이 파이프라인의 앞단을 강화하는 모델이지, 전체 회의록 제품을 한 번에 대체하는 도구가 아닙니다.
두 번째는 한국어 업무 도메인입니다. 공식 수치는 FLEURS 기준입니다. 실제 회사 회의에는 “PoC”, “전환율”, “SKU”, “리드타임”, “2분기 ARR” 같은 혼합 표현이 계속 나옵니다. 병원, 법무, 제조, 금융처럼 전문 용어가 많은 조직은 몇 시간에서 수십 시간 수준의 도메인 음성 데이터로 fine-tuning을 검토해야 합니다.
세 번째는 하드웨어와 운영입니다. 공식 처리량 수치는 단일 H100 기준입니다. 개발자가 로컬 노트북이나 저가 GPU에서 같은 동시 스트림 수를 기대하면 안 됩니다. Jetson 지원 가능성이 언급되더라도, 실제 제품 수준의 지연·발열·메모리 사용량은 별도 측정이 필요합니다.
네 번째는 라이선스와 데이터 정책입니다. 모델 카드는 OpenMDW-1.1을 명시하고 상업적 사용 가능하다고 설명하지만, 기업 배포 전에는 모델별 라이선스, 파생 모델 재배포 조건, 고객 음성 데이터 처리 방침을 법무와 함께 확인해야 합니다. 특히 상담 녹취와 회의록은 개인정보보호법, 녹취 고지, 사내 보안 정책과 맞물립니다.
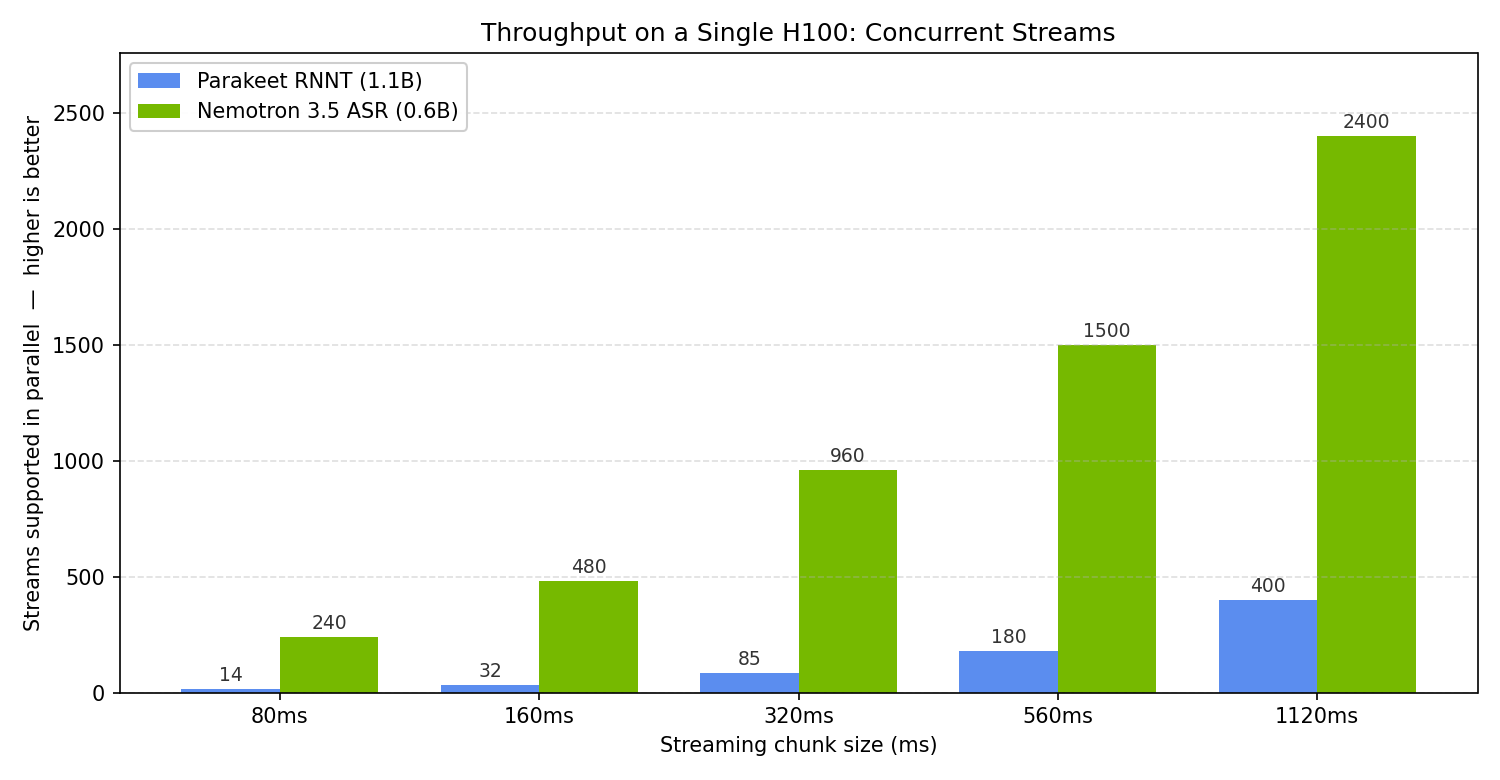
이미지 출처: NVIDIA Hugging Face 모델 카드. 보이스 에이전트와 콜센터에서 중요한 비용 지표가 모델 정확도뿐 아니라 동시 스트림 처리량임을 보여주는 공식 그래프다.
관전 포인트
앞으로 볼 지점은 다섯 가지입니다.
첫째, NIM 출시와 gRPC 스트리밍 지원입니다. NVIDIA의 Hugging Face 블로그는 생산 환경 serving을 위한 NIM 릴리스가 2026년 6월 중 예정되어 있고, gRPC streaming과 Ampere, Hopper, Blackwell, Lovelace, Turing, Volta, Jetson 지원을 언급했습니다. NeMo로 직접 돌리는 실험과 NIM으로 운영하는 제품은 난도가 다릅니다.
둘째, 한국어 독립 벤치마크입니다. 공식 FLEURS 수치는 출발점입니다. 국내 회의실, 전화 상담, 방송 자막, 법정·의료·제조 현장 녹취 같은 실제 데이터에서 Whisper, Qwen3-ASR, Mega-ASR, Parakeet 계열과 비교한 결과가 필요합니다.
셋째, 음성 에이전트 전체 루프입니다. ASR이 빨라져도 LLM 응답과 TTS가 느리면 사용자는 여전히 답답하다고 느낍니다. 반대로 ASR 지연이 줄어들면 LLM이 생각할 시간을 더 벌 수 있습니다. 보이스 에이전트의 경쟁은 모델 하나가 아니라 ASR → reasoning → tool call → TTS 전체 왕복 시간의 경쟁입니다.
넷째, 온프레미스 회의록 시장입니다. 한국 기업은 회의록을 클라우드 API에 보내는 데 민감한 경우가 많습니다. 오픈웨이트 ASR, 사내 GPU, 자체 fine-tuning 조합이 현실화되면 “회의록 SaaS를 쓸 것인가, 사내 음성 AI 스택을 만들 것인가”라는 질문이 더 자주 나올 수 있습니다.
다섯째, NVIDIA의 음성 스택 확장입니다. Nemotron 3.5 ASR은 독립 발표처럼 보이지만, 사실 NVIDIA가 에이전트 입력층까지 넓히는 움직임입니다. 언어모델, 안전 모델, ASR, TTS, NIM, NeMo가 한 묶음으로 굳으면 기업은 특정 폐쇄형 API 하나가 아니라 “NVIDIA 기반 사내 AI 공장”을 선택지로 보게 됩니다.
결론은 간단합니다. Nemotron 3.5 ASR은 한국어 회의록을 완성하는 제품이 아니라, 한국어 음성을 실시간 AI 시스템에 넣기 위한 더 현실적인 부품입니다. 회의록 품질은 여전히 마이크, 화자 분리, 도메인 용어, 요약 검증, 보안 정책에 달려 있습니다. 하지만 한국어가 transcription-ready에 들어가고, 320ms 전후 스트리밍 수치가 공개됐고, 오픈웨이트로 직접 실험할 수 있다는 점은 작지 않습니다.
이제 한국어 보이스 에이전트의 질문은 “가능한가”에서 “어떤 데이터와 검증 루프로 운영할 것인가”로 이동하고 있습니다.
출처 및 더 읽을 거리
- NVIDIA Hugging Face 모델 카드 — Nemotron 3.5 ASR: 모델 공개일, 600M 파라미터, 한국어
ko-KR지원 티어, FLEURS 한국어 CER, 처리량 그래프, NeMo 실행 예시를 확인할 수 있는 공식 원문이다. - Hugging Face Blog by NVIDIA — How to Fine-Tune Nemotron 3.5 ASR for Your Language, Domain, or Accent: fine-tuning 절차, 다국어 지원 목록, NIM 출시 예고, 실제 적용 사례를 NVIDIA 작성자들이 설명한 공식 블로그다.
- NVIDIA Developer Blog — NVIDIA Nemotron 3 Ultra Powers Faster, More Efficient Reasoning for Long-Running Agents: Nemotron 3.5 ASR이 Nemotron 3 Ultra, Content Safety와 함께 어떤 에이전트 스택 맥락에서 공개됐는지 확인할 수 있는 NVIDIA 공식 기술 블로그다.
- NVIDIA NeMo GitHub: Nemotron 3.5 ASR을 불러오고 cache-aware streaming inference 스크립트를 실행하는 개발 프레임워크와 예제 코드의 원본 저장소다.
- arXiv — Pushing the Limits of On-Device Streaming ASR: 영어 Nemotron Speech Streaming 계열을 온디바이스 ASR 후보로 평가한 독립 연구로, 스트리밍 ASR의 정확도·지연·메모리 trade-off를 이해하는 데 도움이 된다.
- AI Insight Hub — 회의 녹음 AI가 자꾸 틀리는 이유: Mega-ASR은 잡음 속 말을 어디까지 살릴까: Nemotron 3.5 ASR과 달리 잡음 많은 녹음 파일 중심 ASR을 다룬 기존 글로, 회의록 ASR 평가 기준을 비교해 볼 수 있다.