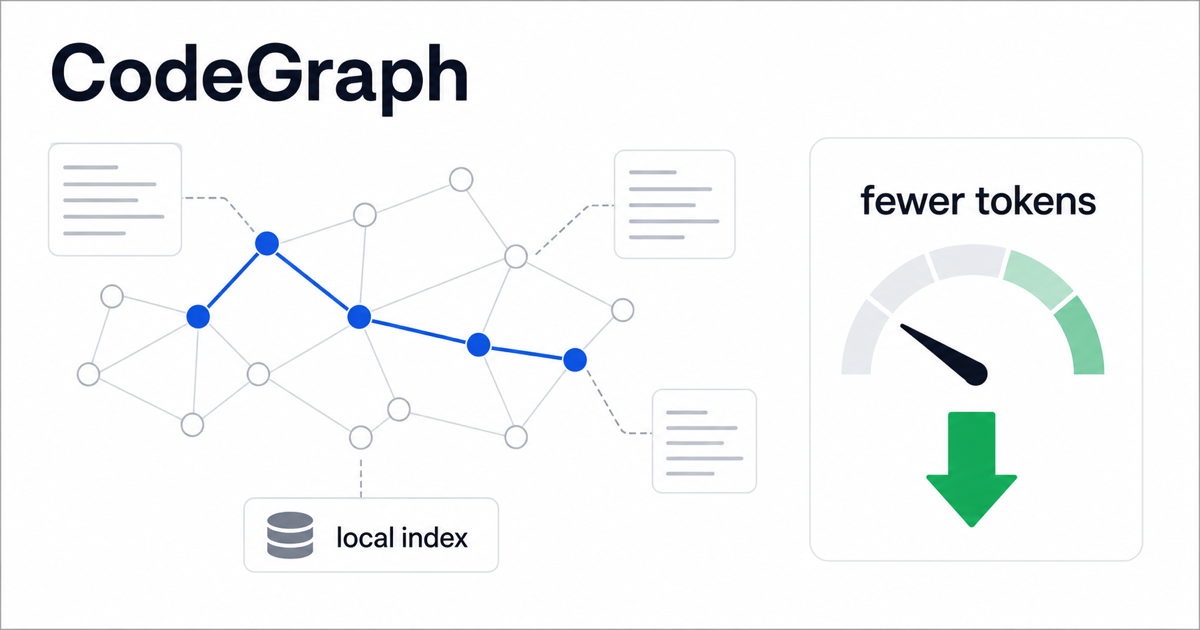
핵심 요약
AI 코딩 비용은 모델 가격표에서만 결정되지 않습니다.
에이전트가 코드를 고치기 전에 무엇을 읽고, 몇 번 검색하고, 얼마나 많은 파일을 다시 훑는지가 실제 청구서를 만듭니다. CodeGraph가 흥미로운 이유도 여기에 있습니다. 더 싼 모델로 갈아타자는 이야기가 아니라, 모델이 저장소를 탐색하는 방식을 바꾸자는 제안이기 때문입니다.
CodeGraph는 로컬 코드베이스를 tree-sitter로 파싱하고, 함수·클래스·호출 관계·import·파일 구조를 SQLite 기반 그래프로 저장한 뒤, MCP 서버와 CLI로 AI 코딩 에이전트에 제공합니다. Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity IDE, Kiro 같은 도구가 파일을 무작정 읽기 전에 “이 함수의 호출자는 어디인가”, “이 라우트는 어떤 핸들러로 이어지는가”, “수정 영향 범위는 어디까지인가”를 그래프에 물어볼 수 있게 만드는 구조입니다.
공식 README 기준 CodeGraph는 2026년 6월 2일 Claude Opus 4.8로 재검증한 벤치마크에서 평균 16% 비용 절감, 47% 토큰 감소, 22% 시간 단축, 58% tool call 감소를 주장합니다. 숫자는 매력적이지만, 그대로 모든 팀에 적용된다고 보면 위험합니다. 같은 README도 7개 오픈소스 저장소, 아키텍처 질문 1개씩, arm당 4회 실행의 median이라는 전제를 밝히고 있습니다.
이 글의 결론은 단순합니다. CodeGraph류 도구는 “AI 코딩이 비싸다”는 문제를 모델 선택 문제가 아니라 컨텍스트 공급 문제로 바꿉니다. 다만 효과를 보려면 팀이 직접 샘플 질의, 토큰 기록, 정확도 검수, 보안 정책까지 함께 설계해야 합니다.
무슨 일이 있었나
CodeGraph는 colbymchenry/codegraph 저장소로 공개된 로컬 우선 코드 인텔리전스 도구입니다. GitHub README는 이 도구를 Claude Code, Cursor, Codex, OpenCode, Hermes Agent, Gemini, Antigravity, Kiro에 의미 있는 “semantic code intelligence” 레이어로 소개합니다.
설치 흐름은 비교적 단순합니다. macOS나 Linux에서는 설치 스크립트를 실행하거나, Node 환경에서는 npm 전역 패키지로 설치할 수 있습니다. 그다음 codegraph install로 에이전트 설정에 MCP 서버를 연결하고, 각 프로젝트에서 codegraph init -i로 .codegraph 인덱스를 만듭니다.
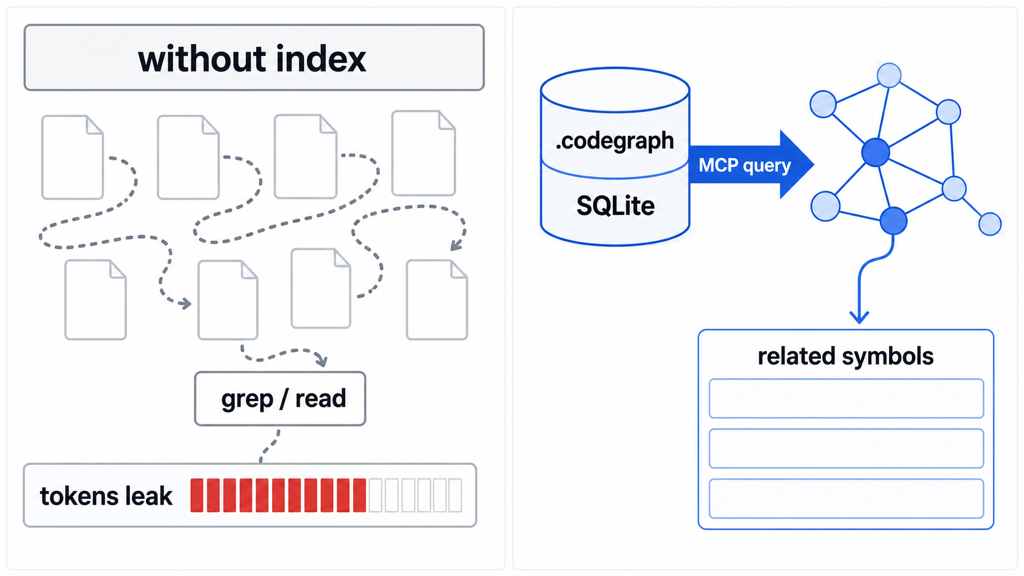
CodeGraph README와 공식 문서를 바탕으로 파일 탐색 루프와 .codegraph SQLite 인덱스 기반 MCP 질의 흐름을 정리한 그림. (이미지: 본 블로그 제작)
CodeGraph 문서는 작동 과정을 네 단계로 설명합니다. 먼저 tree-sitter가 소스 파일을 AST로 파싱합니다. 그다음 함수, 클래스, 메서드, 타입, 호출, import, 상속 같은 노드와 엣지를 추출합니다. 이 정보는 .codegraph/codegraph.db의 로컬 SQLite 데이터베이스에 저장되고, FTS5 기반 전체 텍스트 검색과 함께 사용됩니다. 마지막으로 MCP 서버가 파일 변경을 감지해 인덱스를 최신 상태로 유지합니다.
중요한 점은 이 그래프가 LLM 요약으로 만들어지는 것이 아니라 AST에서 결정적으로 추출된다는 점입니다. 즉 “모델이 한번 읽고 기억한 요약”이 아니라, 코드 구조에서 나온 관계 데이터에 가깝습니다. 이것이 비용 절감 논리의 핵심입니다. 에이전트가 매번 grep, glob, Read를 반복해 구조를 재구성하지 않아도 되면, 입력 토큰과 tool call이 줄어들 수 있습니다.
GitTrend도 2026년 6월 3일 기준 CodeGraph를 트렌딩 저장소 목록에 올렸습니다. 다만 트렌딩 순위나 스타 수는 관심의 신호일 뿐, 제품 효과의 증거는 아닙니다. 실제 도입 판단은 공식 벤치마크 조건과 팀 내부 실험으로 해야 합니다.
사람들이 실제로 겪는 문제
AI 코딩 도구를 써본 개발자라면 비슷한 장면을 겪습니다.
“이 버그 고쳐줘”라고 했는데, 에이전트가 바로 고치지 않습니다. 먼저 파일 목록을 훑고, 비슷한 이름을 검색하고, import를 따라가고, 관련 테스트를 찾고, 다시 다른 파일을 읽습니다. 사람 개발자에게는 당연한 탐색 단계지만, LLM 에이전트에게는 이 과정 하나하나가 토큰과 도구 호출입니다.
문제는 이 탐색이 매번 반복된다는 점입니다. 같은 저장소에서 비슷한 질문을 해도 에이전트는 이전 탐색 결과를 항상 안정적으로 재사용하지 못합니다. 컨텍스트 창이 커져도 해결이 깔끔하지 않습니다. 저장소 전체를 넣으면 비용과 지연시간이 커지고, 관련 없는 파일이 모델의 주의를 흐릴 수 있습니다.
2026년 4월 공개된 “How Do AI Agents Spend Your Money?” 논문은 이 문제를 더 넓게 보여줍니다. 연구진은 SWE-bench Verified에서 8개 frontier 모델의 에이전트 궤적을 분석했고, 에이전트형 코딩 작업이 일반 코드 reasoning이나 code chat보다 1000배 많은 토큰을 소비할 수 있다고 보고했습니다. 또 같은 작업도 실행마다 총 토큰이 최대 30배까지 달라질 수 있고, 더 많은 토큰이 항상 더 높은 정확도로 이어지지는 않는다고 설명했습니다.
이 말은 AI 코딩 비용이 단순히 “입력 100만 토큰당 몇 달러” 문제가 아니라는 뜻입니다. 에이전트가 어떤 순서로 탐색하는지, 실패 후 얼마나 오래 헤매는지, 어떤 파일을 불필요하게 읽는지까지 비용 구조에 들어갑니다.
이전 글 AI 코딩에서 컨텍스트 도구가 중요한 이유에서도 핵심은 “모델에게 더 많이 넣는 것”이 아니라 “필요한 근거를 제대로 고르는 것”이라고 정리했습니다. CodeGraph는 이 흐름의 더 구체적인 예입니다. 검색과 파일 읽기를 그래프 질의로 일부 대체해, 에이전트의 첫 탐색 비용을 줄이려는 시도입니다.
숫자는 어디까지 믿어야 하나
CodeGraph README의 최신 벤치마크는 흥미롭습니다. 7개 실제 오픈소스 저장소를 대상으로 Claude Opus 4.8 headless 실행을 비교했고, CodeGraph MCP 서버가 있는 조건과 없는 조건을 나눴습니다. 각 저장소에는 하나의 아키텍처 질문이 주어졌고, arm당 4회 실행 median을 보고했습니다.
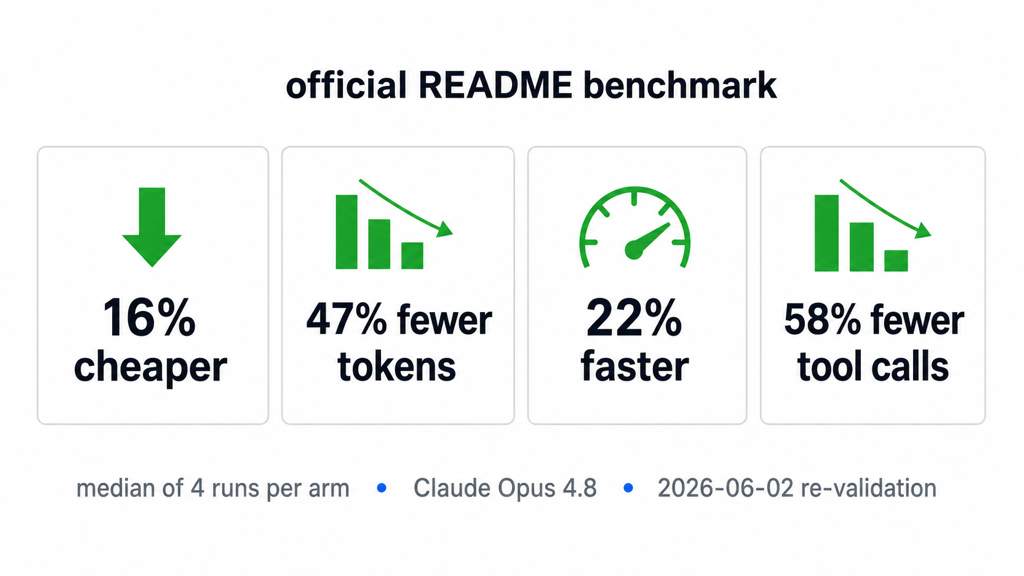
CodeGraph README의 2026-06-02 re-validation 수치와 방법론 주석을 요약한 표. (이미지: 본 블로그 제작)
| 항목 | CodeGraph 공식 README 평균 |
|---|---|
| 비용 | 16% cheaper |
| 총 토큰 | 47% fewer tokens |
| 시간 | 22% faster |
| tool calls | 58% fewer tool calls |
저장소별로 보면 차이가 큽니다. VS Code 예시는 총 토큰이 1.79M에서 640k로 줄어 64% 감소했고, tool calls는 21회에서 4회로 줄었다고 보고됐습니다. Django는 토큰 60% 감소, tool calls 77% 감소입니다. Alamofire는 비용 40% 절감과 토큰 64% 감소가 함께 나왔습니다.
하지만 이 숫자를 “우리 회사도 바로 47% 토큰이 줄어든다”로 읽으면 안 됩니다. README의 방법론을 보면 질문 유형은 아키텍처 이해에 가깝고, 테스트 대상도 특정 오픈소스 저장소입니다. 버그 수정, 대규모 refactor, UI 변경, flaky test 추적, 레거시 모노레포 작업에서는 결과가 달라질 수 있습니다.
또 하나의 포인트는 비용과 토큰 감소가 항상 같은 방향으로 움직이지 않는다는 점입니다. Excalidraw와 Tokio 예시에서는 토큰은 줄었지만 비용은 break-even으로 보고됐습니다. CodeGraph가 여러 작은 grep/read 왕복을 줄이는 대신 큰 MCP 응답을 주면, 캐시와 입력 구조에 따라 실제 달러 비용은 토큰 감소율만큼 내려가지 않을 수 있습니다.
그래서 벤치마크의 의미는 “확정된 절감률”이 아니라 “탐색 단계가 비용의 큰 비중을 차지한다면, 그래프 인덱스가 실험할 만한 레버가 된다”에 가깝습니다.
왜 중요한가
지금까지 AI 코딩 비용을 줄이는 대표적인 방법은 모델을 바꾸는 것이었습니다. 어려운 작업은 큰 모델, 단순 작업은 작은 모델. 이 접근은 여전히 유효합니다. 하지만 에이전트형 코딩에서는 모델 선택만으로 해결되지 않는 비용이 있습니다. 바로 코드베이스 이해 비용입니다.
개발자는 저장소 구조를 어느 정도 기억합니다. “인증은 여기”, “라우팅은 저 파일”, “테스트 fixture는 이 디렉터리”처럼 조직 지식이 있습니다. 반면 에이전트는 매 세션마다 이 지식을 도구 호출로 다시 사야 합니다. 코드 그래프는 이 반복 구매를 줄이려는 장치입니다.
이 변화는 팀 운영에도 영향을 줍니다.
첫째, AI 코딩 도구의 성능 평가가 답변 품질만으로 끝나지 않습니다. 앞으로는 “성공한 PR 하나당 토큰”, “불필요한 파일 읽기 수”, “수정 전 탐색 시간”, “검증 루프당 비용”을 같이 봐야 합니다.
둘째, 컨텍스트 인프라가 개발자 생산성 도구의 일부가 됩니다. 과거에는 코드 검색, 정적 분석, dependency graph가 사람을 위한 도구였습니다. 이제는 에이전트가 읽는 인덱스이기도 합니다. 좋은 인덱스는 에이전트의 판단 품질과 비용을 동시에 바꿀 수 있습니다.
셋째, 보안 기준도 달라집니다. CodeGraph는 로컬 우선이고 문서상 외부 API 키나 외부 서비스 없이 .codegraph SQLite 데이터베이스를 만든다고 설명합니다. 이것은 장점입니다. 하지만 사내 repo에서는 인덱스 파일 자체가 민감한 구조 정보를 담습니다. 함수명, 라우트, import, 호출 관계는 코드 원문보다 덜 민감해 보여도 공격자에게는 충분한 지도입니다.
어떻게 써야 하나
CodeGraph를 팀에 바로 전면 도입하기보다, 작은 파일럿으로 시작하는 편이 안전합니다. 기준은 “설치됐는가”가 아니라 “우리 저장소의 실제 작업 비용을 줄였는가”입니다.
팀 파일럿 체크리스트:
- 저장소 1개를 고른다. 너무 작은 toy repo보다, 에이전트가 평소 탐색에 시간을 쓰는 중간 규모 이상의 repo가 좋다.
- 샘플 질의 5개를 정한다. 예: 인증 흐름 설명, 특정 API 라우트 영향 범위, 한 함수의 호출자 추적, 테스트 파일 찾기, 작은 버그 수정 계획.
- CodeGraph 없는 조건과 있는 조건을 나눠 같은 모델과 같은 프롬프트로 실행한다.
- 총 토큰, 비용, tool calls, 파일 읽기 수, 실행 시간, 답변 정확도를 기록한다.
- “정답률이 유지되면서 비용이 줄었는가”를 본다. 토큰만 줄고 중요한 파일을 놓치면 실패다.
.codegraph디렉터리 보관 정책을 정한다. commit 금지, 백업 제외, 사내 보안 분류를 명시한다.- 설치 스크립트와 MCP 권한을 검토한다. 자동으로 어떤 에이전트 설정을 바꾸는지 확인한 뒤 팀 표준에 맞춘다.

샘플 질의, 전후 비교, .codegraph 정책, 설치 스크립트, MCP 권한 확인 항목을 정리한 체크리스트. (이미지: 본 블로그 제작)
실행 프롬프트도 바꿔야 합니다. CodeGraph는 설치만으로 항상 효과가 나는 도구가 아닙니다. README도 CodeGraph가 직접 질의될 때 효과가 있고, 에이전트가 파일 읽기 subagent를 그대로 돌리면 오버헤드가 될 수 있다고 설명합니다.
복붙용 프롬프트 예시는 이렇습니다.
이 저장소에서는 먼저 CodeGraph MCP 도구로 관련 심볼, 호출자, callee, import 경로, 영향 범위를 확인하세요.
바로 파일을 대량으로 읽지 말고, CodeGraph 결과를 바탕으로 수정 후보 파일을 5개 이하로 좁힌 뒤 보고하세요.
수정은 아직 하지 마세요.
보고서에는 다음을 포함하세요.
- 관련 entry point
- 영향 받을 가능성이 높은 함수와 파일
- 반드시 읽어야 할 파일 목록
- 불확실한 부분
- 다음 단계에서 예상되는 토큰 낭비 요인
이 프롬프트의 목적은 에이전트를 “바로 고치는 사람”이 아니라 “먼저 탐색 비용을 줄이는 조사자”로 두는 것입니다. AI 코딩에서 비용을 줄이는 가장 확실한 방법 중 하나는 수정 전에 탐색 범위를 좁히는 것입니다.
리스크와 한계
첫 번째 한계는 그래프가 코드의 모든 의미를 알지는 못한다는 점입니다. AST 기반 그래프는 함수, import, 상속, 호출 관계에 강합니다. 하지만 런타임 동적 dispatch, reflection, 프레임워크 magic, 빌드 타임 코드 생성, feature flag, DB migration, 권한 정책처럼 정적 구조만으로 설명하기 어려운 영역이 있습니다. CodeGraph 문서는 일부 framework-specific 패턴과 dynamic-dispatch 경계를 synthesizer로 연결한다고 설명하지만, 모든 레거시 패턴을 완벽히 잡는다는 뜻은 아닙니다.
두 번째 한계는 최신성입니다. 파일 watcher와 incremental sync가 있어도, CI 환경이나 대형 모노레포에서는 인덱스가 언제 생성됐고 어떤 commit 기준인지 명확히 관리해야 합니다. 에이전트가 오래된 그래프를 믿고 수정하면 비용 절감이 아니라 버그 생성으로 이어집니다.
세 번째는 보안입니다. 로컬 우선은 좋은 출발점이지만, 설치 스크립트가 agent 설정을 바꾸고 MCP 서버가 코드 구조를 제공한다는 점은 관리 대상입니다. 사내 환경에서는 .codegraph 디렉터리, MCP config, agent permission, multi-repo 모드, CI 캐시 저장 여부를 명시적으로 정해야 합니다.
네 번째는 벤치마크 과신입니다. 공식 수치는 유용한 출발점이지만, 특정 질문 유형과 모델, 저장소에 의존합니다. 특히 실제 업무는 “설명해줘”보다 “고치고 테스트하고 리뷰 가능한 diff를 만들어줘”에 가깝습니다. 이 경우 탐색 토큰은 줄어도 수정·검증·재시도 토큰이 더 큰 비중을 차지할 수 있습니다.
관전 포인트
첫째, CodeGraph류 도구가 단독 제품으로 남을지, Cursor, Claude Code, Codex, GitHub Copilot 같은 주요 코딩 도구의 기본 기능으로 흡수될지 봐야 합니다. 에이전트가 저장소를 매번 읽는 방식은 비용 면에서 비효율적이기 때문에, 코드 그래프나 구조 인덱스는 점점 기본 인프라가 될 가능성이 큽니다.
둘째, 벤치마크가 “설명 질문”에서 “실제 PR 생성”으로 이동하는지 봐야 합니다. 비용 절감 도구의 진짜 가치는 아키텍처 질문 답변보다 성공한 수정 작업에서 나옵니다. 성공한 PR당 총비용, 리뷰 수정 횟수, 테스트 실패율, 보안 사고 가능성을 함께 측정해야 합니다.
셋째, 보안 정책이 따라붙는지 봐야 합니다. 코드 그래프는 코드 원문을 그대로 클라우드에 올리지 않는다는 장점이 있지만, 그래프 자체도 지식 자산입니다. 기업용 도입에서는 로컬 저장, 접근 통제, audit log, 인덱스 삭제, multi-repo 권한 분리가 중요해집니다.
넷째, 모델 회사들의 반응입니다. 긴 컨텍스트 모델은 “많이 넣으면 된다”고 말하고, 코드 그래프 도구는 “먼저 고르고 넣자”고 말합니다. 실제 현장에서는 둘 중 하나가 아니라 둘의 조합이 될 가능성이 큽니다. 긴 컨텍스트는 최종 판단에, 코드 그래프는 탐색과 후보 축소에 쓰이는 식입니다.
AI 코딩 도구가 좋아졌다는 말은 절반만 맞습니다. 좋아진 만큼 더 오래 생각하고, 더 많은 도구를 부르고, 더 많은 토큰을 씁니다. CodeGraph가 던지는 질문은 그래서 중요합니다. 더 똑똑한 모델을 기다리는 것만으로 충분한가. 아니면 모델이 코드를 읽는 길 자체를 다시 설계해야 하는가.
출처 및 참고 자료
- CodeGraph GitHub README: 설치 방법, 지원 에이전트, 공식 벤치마크 수치, 방법론, 지원 언어와 핵심 기능을 확인할 수 있는 원문이다.
- CodeGraph 공식 문서 Introduction: CodeGraph가 tree-sitter, SQLite, MCP, CLI를 통해 로컬 코드 지식 그래프를 제공한다는 기본 설명을 확인할 수 있다.
- CodeGraph 공식 문서 How It Works: extraction, storage, resolution, auto-sync 단계와
.codegraph/codegraph.db저장 구조를 확인할 수 있는 기술 문서다. - arXiv: How Do AI Agents Spend Your Money?: 에이전트형 코딩 작업의 토큰 소비가 왜 예측 어렵고 비용 변동성이 큰지 보여주는 2026년 4월 논문이다.
- arXiv: Codebase-Memory: Tree-Sitter 기반 코드 지식 그래프와 MCP를 이용해 파일 탐색 토큰과 tool call을 줄이는 접근을 평가한 연구 자료다.
- GitTrend: 2026년 6월 3일 기준 CodeGraph가 개발자 관심을 받은 트렌딩 저장소였음을 확인하는 보조 자료다. 트렌딩 순위는 효과 검증이 아니라 관심도 신호로만 사용했다.