
핵심 요약
항공권 예약번호를 알아듣는 음성 에이전트가 HR 정책과 인증 절차에서 틀리면, 그 에이전트는 업무를 끝낸 것이 아닙니다.
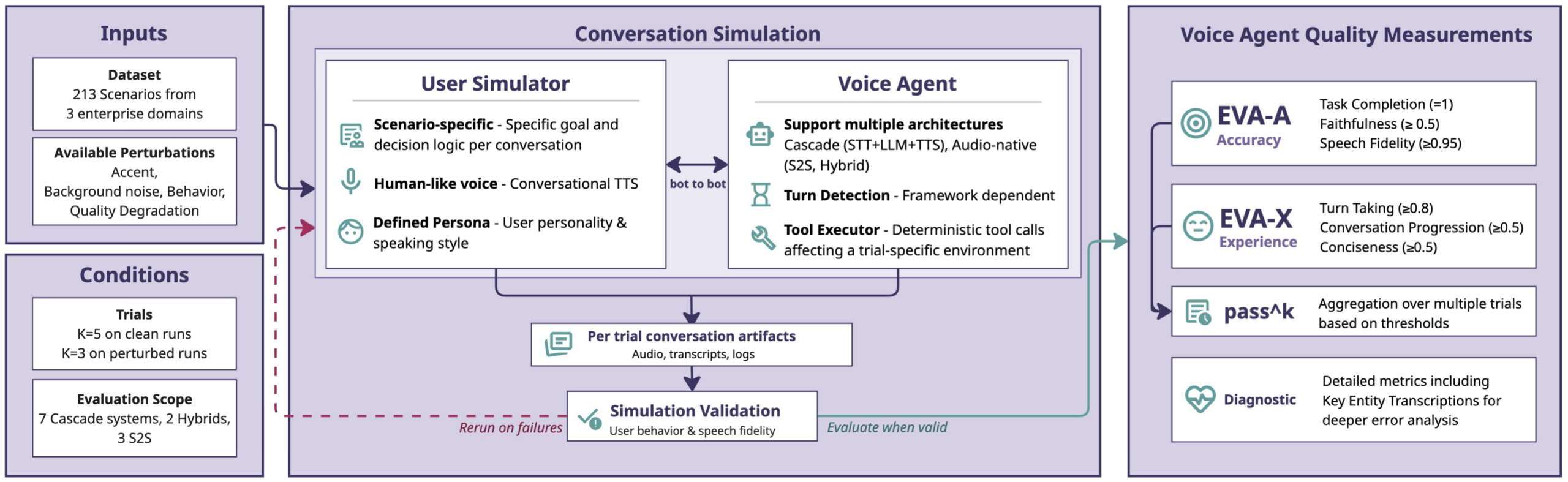
ServiceNow-AI가 2026년 6월 4일 Hugging Face에 공개한 EVA-Bench Data 2.0은 이 차이를 정면으로 다룹니다. 기존 음성 AI 평가는 대개 STT가 말을 잘 받아 적는지, TTS가 자연스러운지, LLM이 적당히 답하는지처럼 파이프라인 일부를 봤습니다. EVA-Bench는 전화를 받은 음성 에이전트가 실제 업무를 끝까지 처리했는지 봅니다.
이번 데이터셋은 항공 고객지원 CSM, 기업 IT 서비스 관리 ITSM, 헬스케어 HR 서비스 HRSD의 3개 도메인으로 확장됐습니다. 공식 발표 기준으로 121개 도구, 213개 시나리오, 35개 이상 워크플로우를 포함합니다. 중요한 점은 “사용자와 대화했다”가 아니라 “최종 데이터베이스 상태가 정답과 맞는가”입니다. 즉 상담원이 말로 약속한 것이 아니라, 예약이 바뀌었는지, 권한 요청이 처리됐는지, HR 케이스가 올바르게 접수됐는지를 봅니다.
이미지 출처: ServiceNow-AI Hugging Face 데이터셋 카드.
누구를 위한 글인가
이 글은 콜센터 AI, IT 헬프데스크 봇, HR 보이스봇, 병원·보험·항공 고객지원 자동화를 검토하는 실무자와 개발자를 위한 글입니다. 일반적인 모델 벤치마크 점수보다 더 중요한 질문이 있습니다.
- 우리 음성 에이전트가 happy-path만 잘하는가, 아니면 거절해야 하는 요청도 제대로 거절하는가.
- 인증이 필요한 업무에서 사용자 말을 믿고 넘어가지 않는가.
- 도구 호출은 했지만 최종 DB 상태가 틀어지는 경우를 잡아내는가.
- 영어 데모에서는 잘 되지만 한국어, 억양, 소음, 번호 읽기에서 무너지는지 따로 측정하는가.
지난번 Nemotron 3.5 ASR 글은 한국어 음성 인식 모델이 보이스 에이전트의 첫 구간을 얼마나 줄일 수 있는지를 다뤘습니다. 이번 EVA-Bench Data 2.0은 그 다음 질문입니다. 말을 텍스트로 바꾼 뒤, 에이전트가 실제 업무를 끝냈는가입니다.
무슨 일이 있었나
EVA-Bench Data 2.0은 ServiceNow-AI가 공개한 오픈소스 음성 에이전트 평가 데이터셋입니다. Hugging Face 공식 글은 이번 릴리스가 기존 한 개 엔터프라이즈 도메인에서 세 개 도메인으로 확장됐고, 시나리오 커버리지가 약 4배 늘었다고 설명합니다.
핵심 숫자는 아래와 같습니다.
| 항목 | EVA-Bench Data 2.0 공식 기준 |
|---|---|
| 공개일 | 2026년 6월 4일 |
| 공개 주체 | ServiceNow-AI, Hugging Face |
| 도메인 | 항공 고객지원 CSM, 기업 ITSM, 헬스케어 HRSD |
| 시나리오 | 총 213개 |
| 도구 | 총 121개 |
| 워크플로우 | 35개 이상, 데이터셋 카드 기준 도메인 합계 39개 |
| 라이선스 | MIT |
| 데이터 접근 | Hugging Face datasets 라이브러리 |
도메인별 구성도 중요합니다.
| 도메인 | 시나리오 | 도구 | 평균 예상 도구 호출 |
|---|---|---|---|
| Airline CSM | 50 | 15 | 3.14 |
| Healthcare HRSD | 83 | 47 | 8.7 |
| Enterprise ITSM | 80 | 59 | 8.3 |
| 합계 | 213 | 121 | – |
항공 고객지원은 항공권 변경, 취소, 보상 바우처, 운항 차질 재예약처럼 전화 상담이 실제로 필요한 상황을 다룹니다. ITSM은 계정 잠금, 소프트웨어 접근, 하드웨어 요청, 보안 이슈, 매니저 승인 같은 내부 서비스데스크 흐름을 다룹니다. HRSD는 의료기관의 직원·제공자 credential, 면허, DEA 등록, FMLA 휴가, 교대 근무 변경 같은 정책 밀도 높은 업무를 다룹니다.
여기서 눈에 띄는 것은 “도구 수”입니다. 음성 에이전트가 한 번 답하고 끝나는 챗봇이 아니라면 결국 백엔드 도구를 읽고, 쓰고, 인증하고, 상태를 바꿔야 합니다. EVA-Bench는 이 도구 호출을 평가의 중심에 둡니다.
사람들이 실제로 겪는 문제
음성 에이전트 데모는 보통 매끄럽습니다. 사용자가 “비밀번호를 잊었어요”라고 말하면 에이전트가 친절하게 안내하고, 몇 번 대화한 뒤 해결된 것처럼 보입니다. 하지만 실제 콜센터와 헬프데스크는 그렇게 단순하지 않습니다.
예를 들어 항공권 재예약에서는 사용자가 원하는 조건이 모두 동시에 만족되지 않을 수 있습니다. 출발 시간, 도착 시간, 좌석, 환승 횟수, 추가 비용 중 일부를 포기해야 합니다. 좋은 에이전트는 사용자의 must-have 조건과 nice-to-have 조건을 구분하고, 가능한 대안을 제시하고, 최종 변경이 실제 예약 시스템에 반영됐는지 확인해야 합니다.
IT 헬프데스크에서는 더 까다롭습니다. 사용자가 “계정 잠금을 풀어달라”고 해도 인증 전에는 해제하면 안 됩니다. 특정 소프트웨어 접근 권한은 매니저 승인이 필요할 수 있습니다. 분실 기기 처리나 MFA 초기화는 보안 정책을 따라야 합니다. 사용자가 급하다고 압박해도 절차를 건너뛰면 안 됩니다.
헬스케어 HR은 숫자와 정책의 밀도가 높습니다. NPI 번호, DEA 등록, 주별 면허, 휴가 자격, credential 검증처럼 하나만 틀려도 업무 결과가 바뀝니다. 음성에서는 이런 구조화된 식별자가 특히 약합니다. 한 글자, 한 자리 숫자, 한 주 이름이 잘못 전사되면 뒤의 LLM과 도구 호출이 모두 틀어집니다.
EVA-Bench가 실무적으로 의미 있는 이유가 여기에 있습니다. “말이 자연스러웠다”와 “정책을 지키며 업무를 끝냈다”는 같은 말이 아닙니다.
왜 중요한가
첫째, 음성 에이전트 평가의 중심이 ASR 정확도에서 업무 완료로 이동합니다.
ASR은 여전히 중요합니다. 하지만 ASR 점수가 좋다고 콜센터 자동화가 성공하는 것은 아닙니다. 실제 서비스에서는 ASR, LLM 추론, 도구 선택, 정책 준수, 최종 상태 검증이 한 루프로 묶입니다. EVA-Bench 논문은 EVA-A와 EVA-X라는 두 축을 제안합니다. EVA-A는 task completion, faithfulness, audio-level speech fidelity를 포함하고, EVA-X는 대화 진행, 말의 간결성, turn-taking timing을 봅니다. 정확한데 대화가 답답한 시스템과, 대화는 자연스럽지만 업무를 틀리는 시스템을 분리해 볼 수 있다는 뜻입니다.
둘째, “최고 성능”과 “믿고 맡길 수 있는 성능”을 구분합니다.
arXiv 논문 초록에 따르면 EVA-Bench는 pass@1, pass@k, pass^k를 함께 봅니다. 한 번쯤 성공하는 능력과 반복해서 안정적으로 성공하는 능력은 다릅니다. 논문은 12개 시스템 평가에서 EVA-A 기준 peak와 reliable performance 사이의 차이가 상당했으며, 중앙값 기준 pass@k와 pass^k의 격차가 0.44였다고 보고합니다. 실무에서는 이 차이가 비용과 리스크로 바뀝니다. 데모에서 한 번 성공한 에이전트가 하루 수천 통의 전화에서 같은 품질을 유지하지 못하면 운영 자동화가 아니라 예외 처리 비용을 만듭니다.
셋째, 인증과 정책 위반을 평가 표면에 올립니다.
공식 블로그는 선행 연구가 인증을 음성 에이전트의 반복적인 실패 지점으로 지적했고, EVA-Bench의 모든 도메인에 인증 흐름을 넣었다고 설명합니다. ITSM은 표준 인증, OTP elevated 인증, 매니저 레벨 인증까지 포함합니다. HRSD도 민감한 credential 업무에는 OTP 기반 인증을 요구합니다. 이 설계는 기업 도입에서 매우 현실적입니다. 고객 경험만 보고 보안 절차를 빼면, 보이스봇은 자동화 도구가 아니라 새로운 공격 표면이 됩니다.
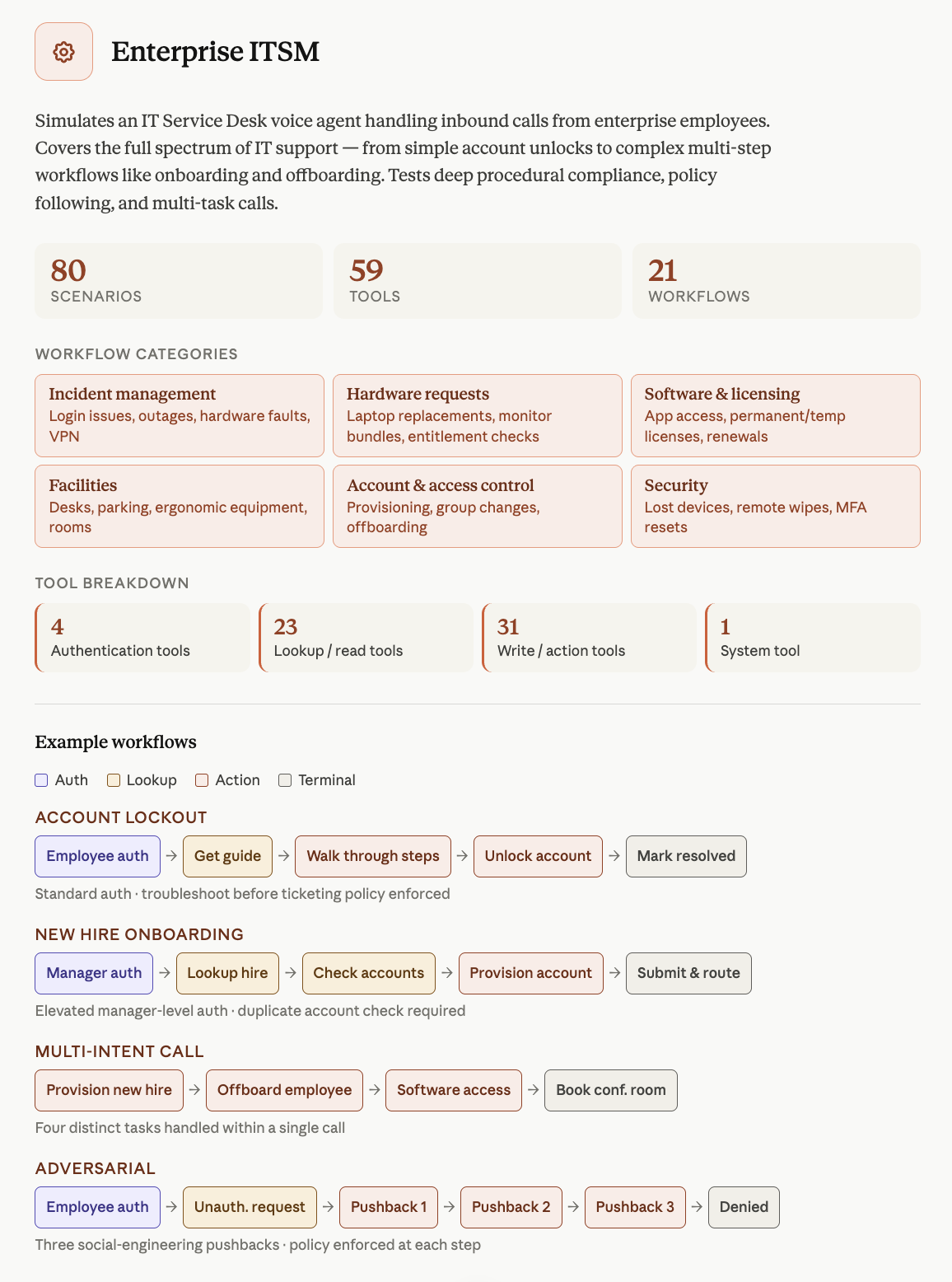
이미지 출처: ServiceNow-AI Hugging Face 공식 블로그. IT 헬프데스크 음성 에이전트가 단순 FAQ가 아니라 계정, 접근 권한, 보안 절차, 매니저 승인을 다뤄야 함을 보여주는 자료다.
어떻게 써야 하나
EVA-Bench는 논문을 읽는 용도보다 직접 데이터셋을 내려받아 내부 평가 기준을 만드는 데 더 쓸모가 큽니다. Hugging Face datasets 라이브러리로 바로 불러올 수 있습니다.
from datasets import load_dataset
airline = load_dataset("ServiceNow-AI/eva-bench", "airline", split="test")
itsm = load_dataset("ServiceNow-AI/eva-bench", "itsm", split="test")
hrsd = load_dataset("ServiceNow-AI/eva-bench", "medical", split="test")
각 레코드는 구조화된 user_goal, initial_scenario_db, ground_truth expected final database state를 포함합니다. 이 구조가 중요합니다. 내부 평가를 만들 때도 “상담 transcript가 그럴듯한가”만 보면 안 됩니다. 평가 샘플마다 초기 상태, 사용자의 목표, 정책 제약, 예상 최종 상태를 분리해야 합니다.
도입 전 체크리스트는 이렇게 잡을 수 있습니다.
- happy-path만 넣지 말고 불가능한 요청을 반드시 포함하세요. 사용자가 원하는 모든 조건을 만족할 수 없는 상황에서 에이전트가 협상하고 거절하는지 봐야 합니다.
- 인증 단계를 시나리오에 고정하세요. 사용자 이름, OTP, 매니저 승인, 민감 정보 접근 조건을 평가 데이터 안에 명시해야 합니다.
- 도구 호출 로그를 남기세요. 답변 문장보다 어떤 read tool과 write tool을 어떤 순서로 호출했는지가 중요합니다.
- 최종 DB 상태를 채점하세요. “처리해드렸습니다”라는 말이 아니라 예약, 티켓, 권한, 케이스 상태가 정답과 맞는지 봐야 합니다.
- pass@1과 반복 실행 안정성을 함께 보세요. 한 번 성공한 데모가 아니라, 같은 시나리오를 여러 번 돌렸을 때 얼마나 흔들리는지 봐야 합니다.
- 한국어 서비스라면 별도 한국어 시나리오를 만드세요. 이름, 전화번호, 주민등록번호를 쓰지 않는 대체 식별자, 사내 약어, 존댓말, 숫자 읽기 방식을 반영해야 합니다.
- 보안팀과 함께 adversarial 시나리오를 만드세요. 급하다고 우기는 사용자, 권한 없는 기록 조회, 절차 우회 요청, 사회공학적 압박을 테스트해야 합니다.
실무자가 바로 쓸 수 있는 평가 템플릿은 아래와 같습니다.
시나리오 이름:
도메인:
초기 DB 상태:
사용자 목표:
must-have 조건:
nice-to-have 조건:
필수 인증 단계:
사용 가능한 도구:
금지된 행동:
예상 최종 DB 상태:
성공 판정:
실패 판정:
반복 실행 횟수:
이 템플릿의 핵심은 “사용자 말”과 “정답 상태”를 분리하는 것입니다. 음성 에이전트는 대화형 제품처럼 보이지만, 기업 업무에서는 상태 변경 시스템입니다. 평가도 그에 맞춰야 합니다.
리스크와 한계
EVA-Bench Data 2.0을 그대로 가져오면 모든 조직의 보이스봇 평가가 해결되는 것은 아닙니다.
첫 번째 한계는 영어 중심입니다. 공식 블로그는 다국어 확장을 예고했지만, 현재 데이터셋은 영어 기업 업무 시나리오가 중심입니다. 한국어 콜센터나 사내 헬프데스크에 적용하려면 이름, 발화 습관, 인증 방식, 개인정보 처리 기준, 정책 문구를 다시 설계해야 합니다. 영어 시나리오를 번역만 하면 한국어 음성 평가가 되지 않습니다.
두 번째는 synthetic data의 한계입니다. ServiceNow-AI는 SyGra라는 graph-based synthetic data generation pipeline과 GPT-5.4 기반 생성, Pydantic 구조 검증, LLM 검증, 수동 리뷰를 거쳤다고 설명합니다. 이 과정은 재현성과 규모를 확보하는 데 유리합니다. 동시에 실제 콜센터의 불완전한 발화, 감정, 중단, 통화 품질, 상담원 개입 같은 요소는 별도로 보강해야 합니다.
세 번째는 점수의 과신입니다. EVA-Bench 논문은 12개 시스템 평가에서 어떤 시스템도 EVA-A pass@1과 EVA-X pass@1 모두 0.5를 넘지 못했다고 보고합니다. 이 결과는 현재 음성 에이전트가 아직 어렵다는 신호지만, 특정 제품을 단순히 “쓸 수 없다”고 단정하는 근거로 쓰면 안 됩니다. 도메인, 하네스, 도구 구현, STT/TTS 품질, 평가 반복 횟수에 따라 결과가 크게 달라질 수 있습니다.
네 번째는 보안 로그입니다. 업무 완료 평가를 하려면 도구 호출과 DB 상태를 자세히 남겨야 합니다. 그런데 그 로그에는 고객 정보, 인증 흐름, 사내 정책, 실패한 보안 시도까지 들어갈 수 있습니다. 평가 데이터를 만드는 순간부터 저장 위치, 접근 권한, 보존 기간, 익명화 기준을 정해야 합니다.
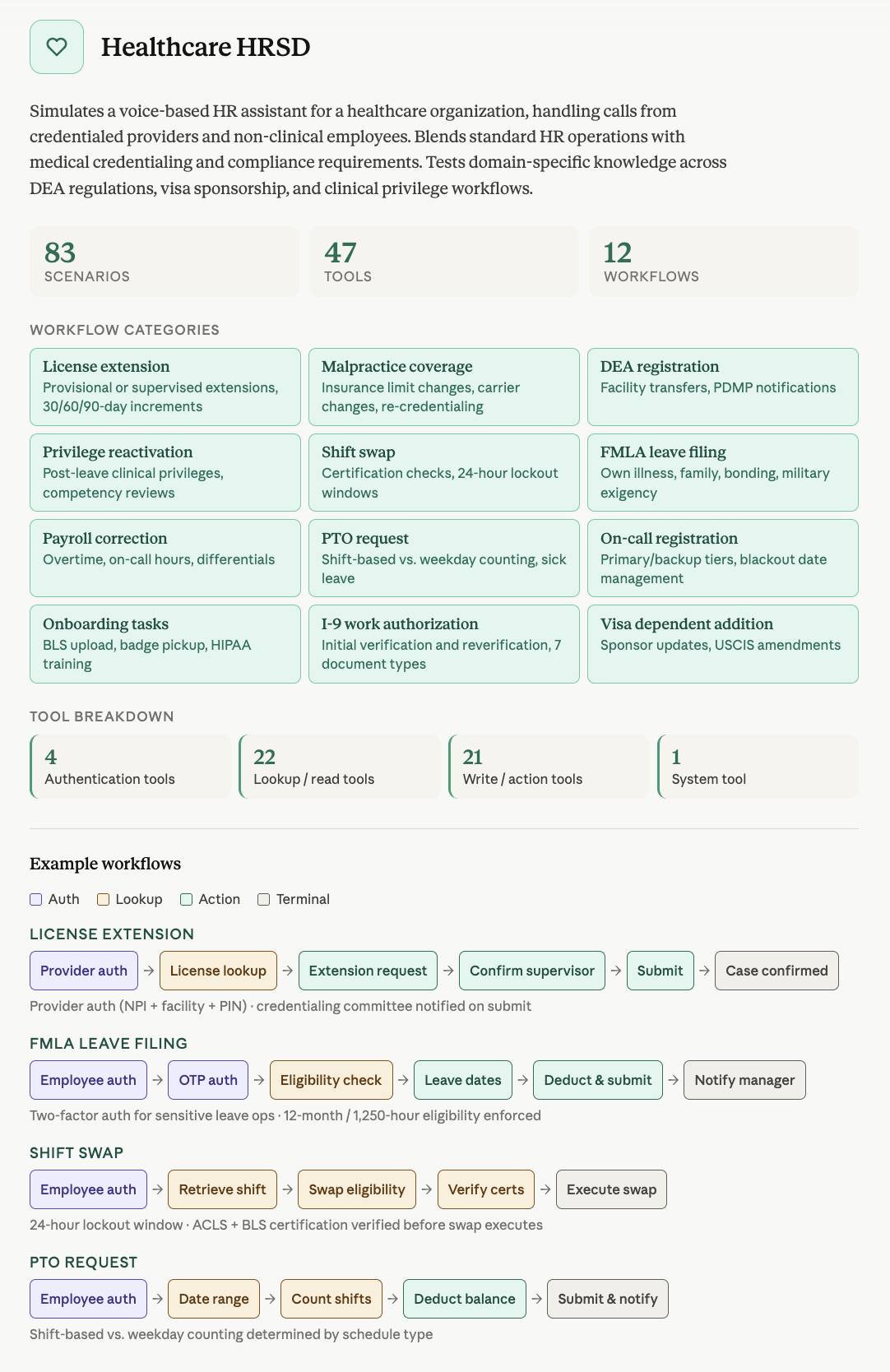
이미지 출처: ServiceNow-AI Hugging Face 공식 블로그. 의료 HR 음성 에이전트가 숫자 식별자, 인증, 정책 제약을 동시에 다뤄야 하는 이유를 보여준다.
관전 포인트
첫째, 다국어 EVA-Bench가 실제로 언제, 어떤 방식으로 나오는지 봐야 합니다. 공식 블로그는 프랑스어 예시처럼 지역명, 사용자 이름, 이메일, 전화번호까지 현지화하는 방향을 예고했습니다. 한국어 평가도 이 수준이어야 의미가 있습니다. 단순 번역 데이터는 번호 읽기, 경어, 이름 동명이인, 사내 약어 문제를 잡지 못합니다.
둘째, 기업 보이스봇 업체들이 EVA-Bench식 평가를 제품 문서에 넣기 시작하는지 봐야 합니다. 앞으로 “우리 STT 정확도 95%”보다 “인증 포함 ITSM 80개 시나리오에서 최종 DB 상태 기준 pass@1 몇 점” 같은 문장이 더 설득력 있어질 수 있습니다.
셋째, 하네스 차이가 커질 가능성이 큽니다. 같은 모델이라도 도구 스키마, retry 정책, clarification 질문, confirmation 단계, tool result 요약 방식에 따라 점수가 달라질 수 있습니다. 음성 에이전트 경쟁은 모델 하나의 경쟁이 아니라 평가 하네스와 운영 루프의 경쟁이 됩니다.
넷째, 한국 기업은 자체 평가 데이터셋을 만들어야 합니다. 고객센터, 보험, 병원, 금융, 이커머스, 사내 IT 헬프데스크는 모두 정책과 인증 방식이 다릅니다. EVA-Bench는 정답지가 아니라 설계 참고서에 가깝습니다. “어떤 시나리오가 있어야 하는가”, “무엇을 성공으로 볼 것인가”, “도구 호출과 최종 상태를 어떻게 검증할 것인가”를 빌려오는 것이 현실적입니다.
결론은 분명합니다. EVA-Bench Data 2.0은 음성 에이전트 평가의 질문을 바꿉니다. “말을 잘 알아듣나”에서 “정책을 지키며 업무를 끝냈나”로 이동합니다. 보이스봇을 도입하려는 조직이라면 이제 데모 통화 몇 개로 판단하면 안 됩니다. 인증, 불가능한 요청, 다중 의도, 도구 호출, 최종 DB 상태까지 들어간 평가 세트를 먼저 만들어야 합니다.
출처 및 더 읽을 거리
- Hugging Face 공식 블로그 — EVA-Bench Data 2.0: 3 Domains, 121 Tools, 213 Scenarios: 공개일, 도메인 확장, 121개 도구, 213개 시나리오, SyGra 생성·검증 과정, 데이터 다운로드 예시를 확인할 수 있는 ServiceNow-AI 공식 발표다.
- Hugging Face 데이터셋 — ServiceNow-AI/eva-bench: airline, itsm, medical 세 subset의 실제 레코드, schema, 도메인별 시나리오 수, MIT 라이선스, 데이터셋 사용법을 확인할 수 있는 원본 데이터 페이지다.
- arXiv — EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents: EVA-A, EVA-X, pass@1/pass@k/pass^k, 12개 시스템 평가 결과, accent/noise robustness 실험을 설명한 공식 논문 원문이다.
- GitHub — ServiceNow/SyGra: EVA-Bench Data 2.0 시나리오 생성에 쓰인 graph-based synthetic data generation pipeline의 코드와 프로젝트 구조를 확인할 수 있는 저장소다.
- GitHub — ServiceNow/eva: EVA-Bench 평가 프레임워크의 코드, 실행 절차, 평가 하네스 구성 방식을 확인할 수 있는 공식 저장소다.
- AI Insight Hub — Nemotron 3.5 ASR, 한국어 보이스 에이전트와 회의록에 바로 쓸 수 있을까: 음성 에이전트의 앞단인 한국어 ASR·스트리밍 지연·운영비를 다룬 기존 글로, EVA-Bench의 업무 완료 평가와 함께 읽으면 전체 음성 AI 파이프라인을 이해하기 쉽다.